数据聚合
数据来源
依旧按照前面建的 bloggers 来
ES 提供了多种聚合方式,因为处理时要对整个字段进行归类处理,所以被聚合的字段是不可分词的,必须是(关键字、数值、日期、布尔)类型的。
- Bucket桶聚合:文档分组
- TermAggregation: 按照字段值分组
- DateHistogram: 按照日期阶梯分组(一天一组、一周一组等)
- Metric度量聚合:计算最值、平均值等
- AVG: 平均值
- MAX: 最大值
- MIN: 最小值
- ...
- STATS:同时求 MAX、MIN、SUM...
- PIPELINE管道聚合: 对其他聚合的结果做二次聚合(使用较少,这里不做说明)
# Bucket桶聚合
# term
首先看一下聚合的语法模板
GET /${索引名}/_search
{
"aggs": {
"${(String) 自定义聚合名}": {
"terms": {
"field": "${(String) 聚合字段}",
"size": "${(Integer) 显示出的条数}",
"order": {
"_count": "${(String) 按照数量的排序规则 asc/desc(默认)}"
}
}/*,
"aggs": "${(Object) 子聚合}"
*/
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
如我给 age 做了个聚合,希望按其分组展示条数,事实上我的数据很少仅用作演示,这个结果就是有两条 21 的有一条 22 的(外层的 size=0 没有作用,仅是不展示 hits 里面的数据内容而已)

当然也可以通过外部添加 query 来组装聚合与查询。
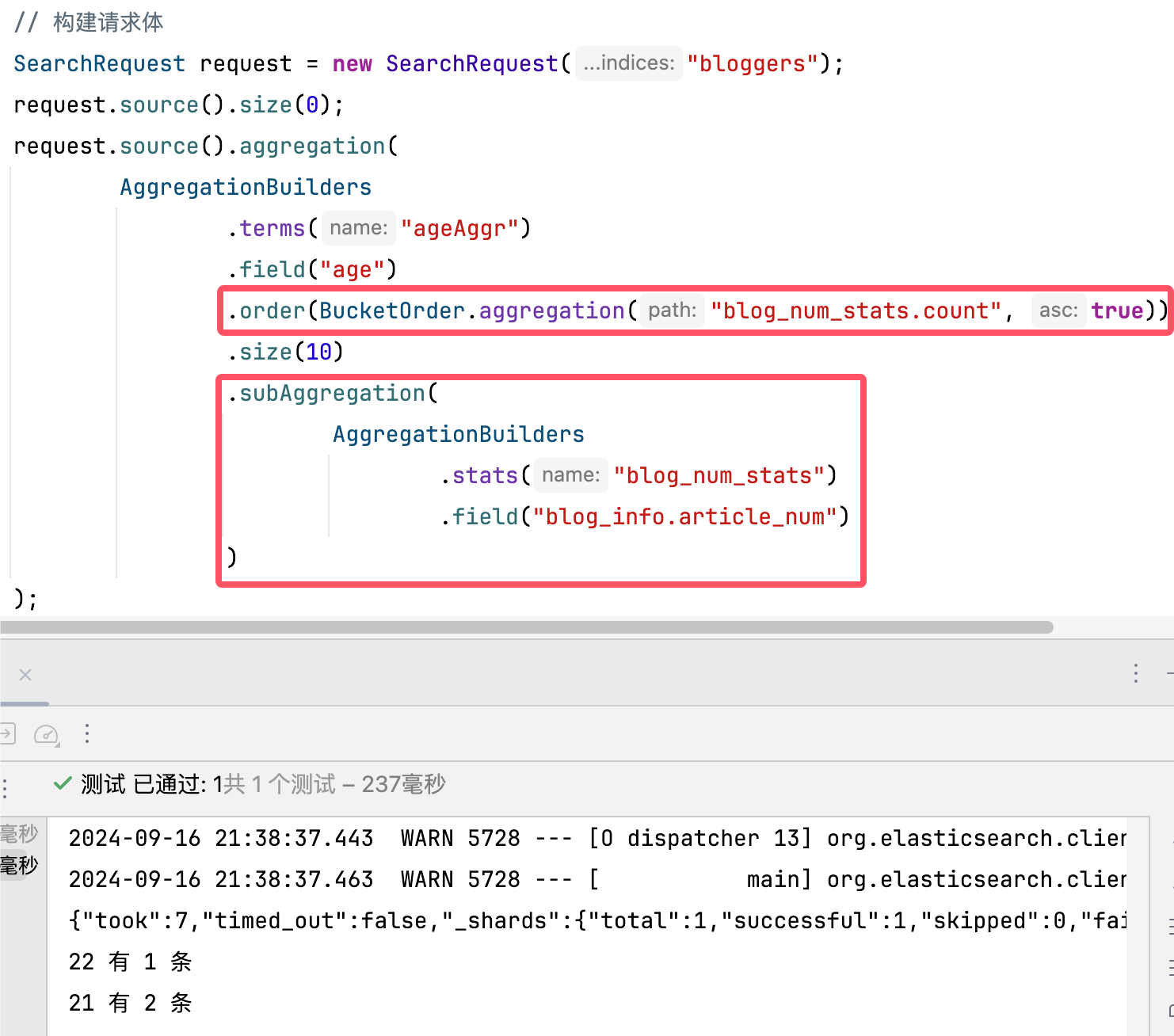
对于 Restful-API 实现来说,一样地根据提到的 RestClient 方法共性 ,基本可以确定使用 request.source().aggregation,而里面的内容写法如下
request.source().aggregation(
AggregationBuilders
.terms("${(String) 自定义聚合名}")
.field("${(String) 聚合字段}")
.size("${(Integer) 显示出的条数}")
);
2
3
4
5
6
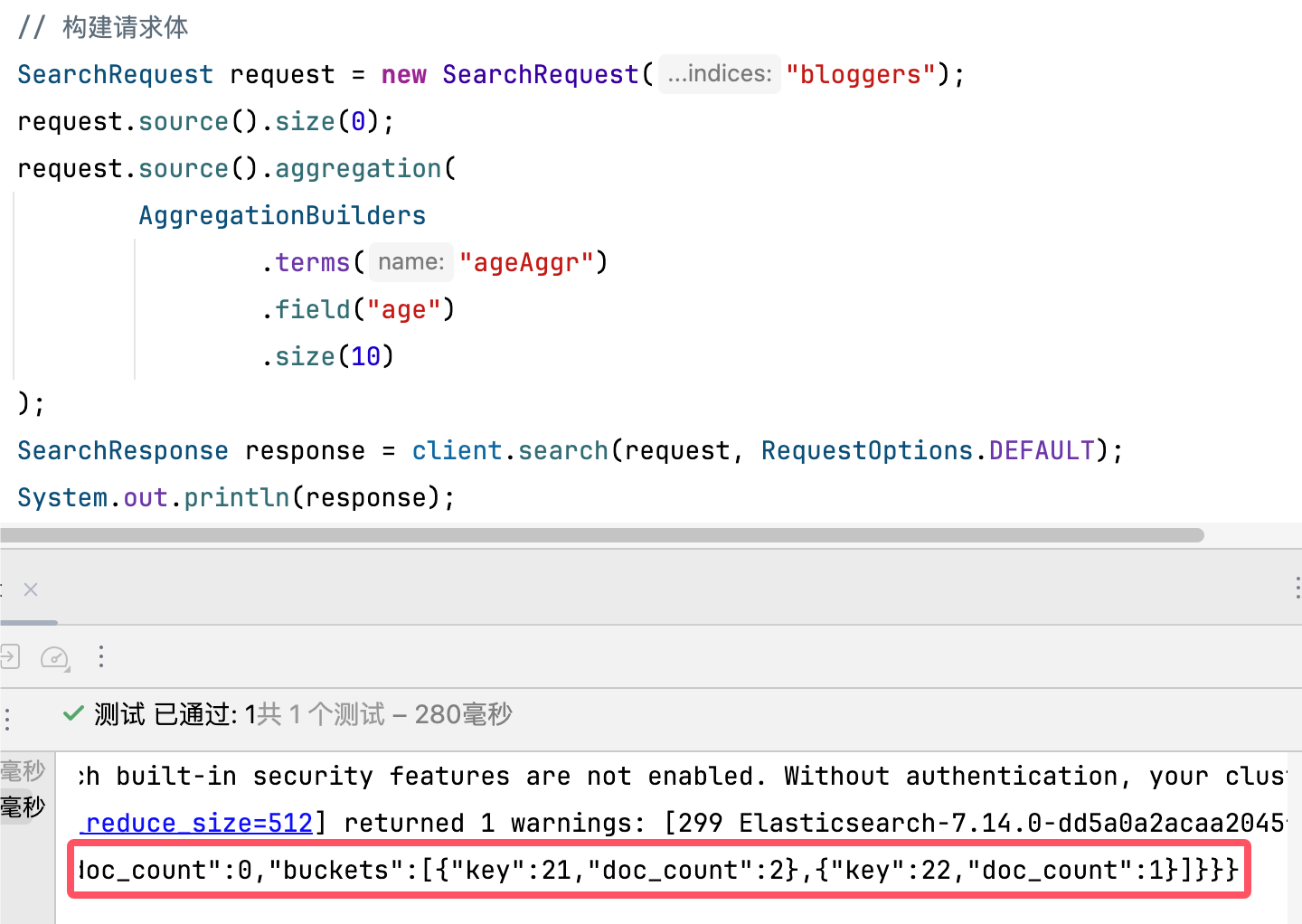
可以看到这一部分跟我们用 DSL 获取的是一样的,似乎看起来要自己解析,其实有更轻松的办法。
观察前面的响应,在 aggregations 下的字段就是我们起名的了,联想到 Map 的 key,这里 response.getAggregations 的下一步就应该 get("${自定义聚合名}") 了,然后能拿到 buckets 并遍历输出内容,整体模板如下。
Terms terms = response.getAggregations().get("${(String) 自定义聚合名}");
terms.getBuckets().forEach(bucket -> {
...
});
2
3
4
和响应都一样的,看一下这里的使用
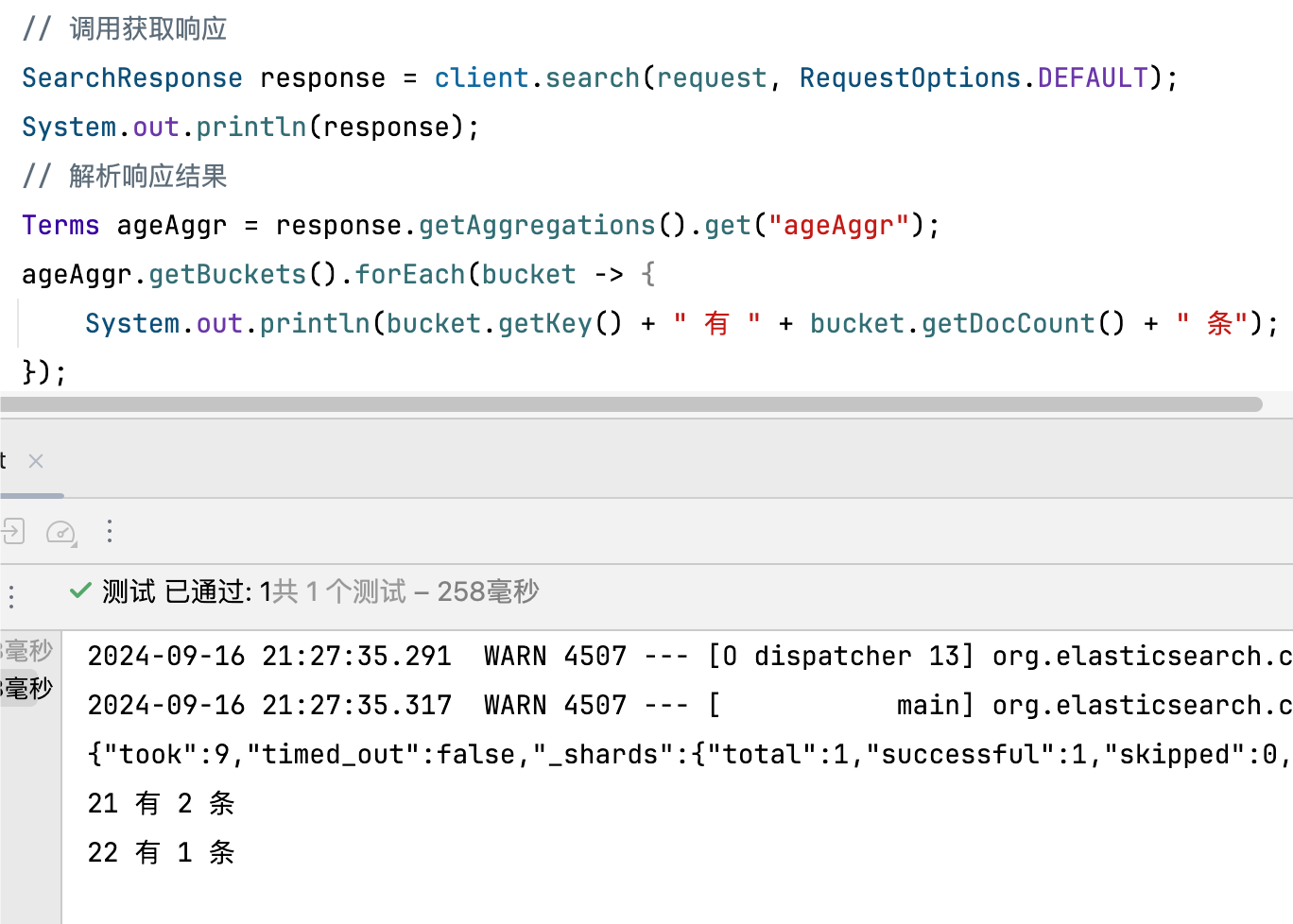
# Metrics度量聚合
根据上面添加子聚合的方式,我们可以在外层依然使用 age 聚合。
内层新定义一个聚合,功能为对聚合后的每一组结果,对博文数量进行计算与统计(用 stats 更全面地展示)
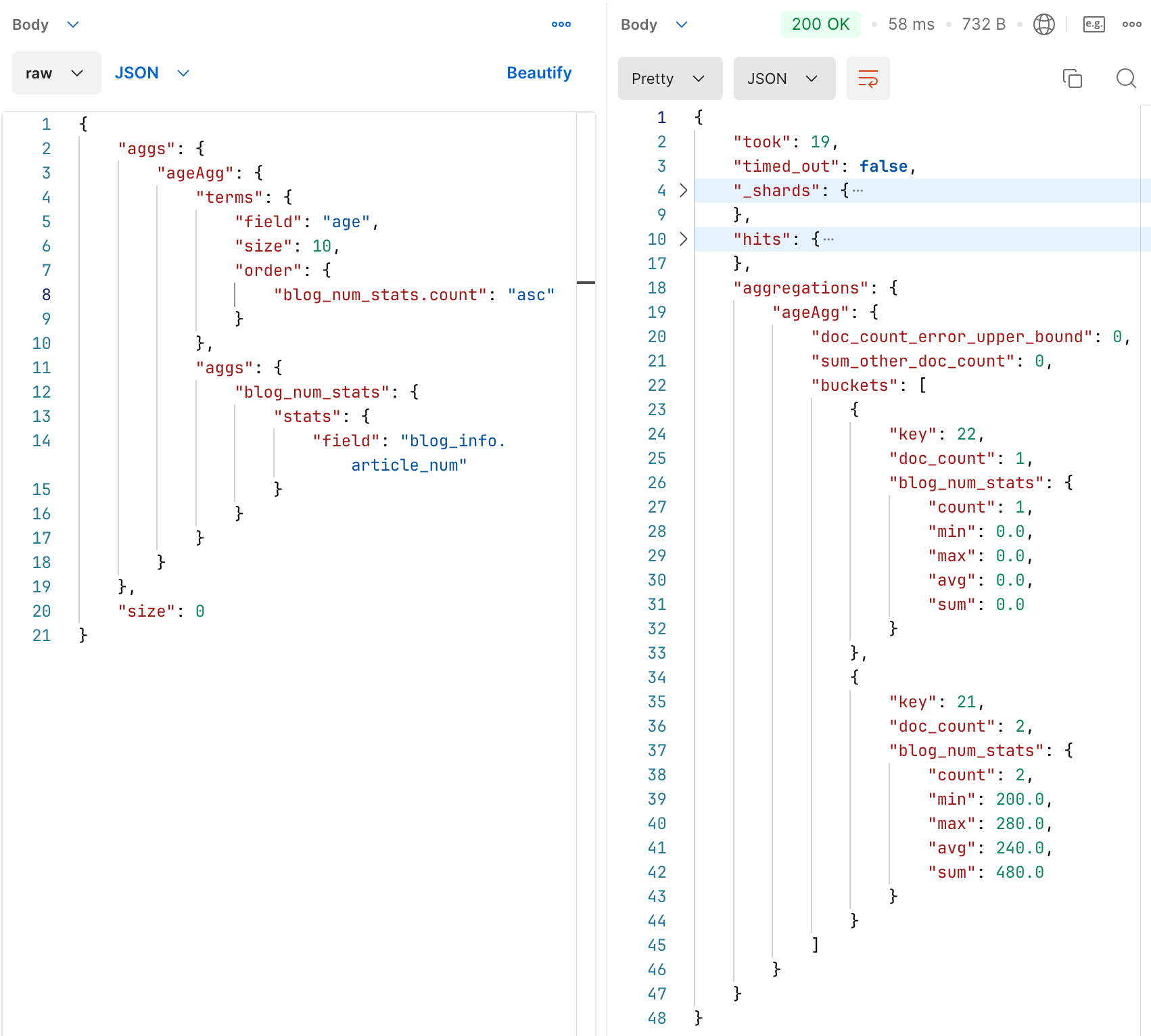
这里每个年龄的博文数量就都在 aggregations.ageAgg.buckets 内被列出来了,并且还通过自定义的博文数量聚合名称,按每条聚合结果的 count 对所有做了一次升序排序。
Restful-API 比葫芦画瓢照着照着补全也可以写出来,无非就是加了个子聚合,然后也尝试一下添加 order