ES基础与安装
# 基本介绍
ElasticSearch(ES) 来自于 ElasticStack(ELK) 中,是 ELK 的核心组件,负责数据的存储、搜索与分析。
ELK 还有其他的一些组件,有负责数据可视化的 Kibana 、负责数据抓取的 Logstash 和 Beats。
ES 的底层是一个 Java 的搜索引擎类库 Lucene,由 Apache 公司研发,ES 在其基础上实现了分布式并提供了 Restful 借口可以被任何语言调用。
# 倒排索引
MySQL 中用的是正排索引,也就是如果在 id 字段创建索引,可以根据 id 找到某条记录。
ES 中使用的是倒排索引,可以根据一个**文档(类似于记录)**的某些内容来找到 id 并获取到整个文档,并且 ES 中的文档是以 JSON 格式存储的,比如有下面这些数据:
{
"id": 1,
"user": "snopzyz",
"age": 21
},
{
"id": 2,
"user": "zhangyize",
"age": 21
},
{
"id": 3,
"user": "demo",
"age": 20
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
那么要对 age 建立倒排索引时,会生成如下这份对应关系表:
| 词条 | 文档id列表 |
|---|---|
| 21 | 1,2 |
| 20 | 3 |
一般不同类型的文档会放到不同的索引库,比如还有一份数据有:
{
"id": 1,
"animal": "cat",
"voice": "miaomiao~"
}
{
"id": 2,
"animal": "dog",
"voidce": "wangwang!"
}
2
3
4
5
6
7
8
9
10
这份数据就有别于我们上面的那份数据,因此会生成并放到另一份索引中,因此索引可以被视为 MySQL 中的库,索引对文档的约束信息可以视为 MySQL 中表的字段结构
索引库对应的是MySQL中的database,本来应该有表也就是es中的type,但是es一直在考虑删除type,在7.0后type也出现了是否开启的选择开关,所以后面就不说type这个概念了,按一个库就是一个type来看。
这种索引方式更能提高检索效率,因为可以直接通过词条找到关联的文档都有哪些,且在类似于模糊查询的场合它不用像 MySQL 一样进行全文扫描。
但由于它对事物功能的缺乏无法保证脏数据的消失,所以一般工作中会对它和 MySQL 双写,结合在一起使用。
# 安装 ES
# Docker 安装
在 docker 中部署运行 es,先建一个 docker 网:
docker network create es
然后再拉取一个 es 镜像并运行:
# 拉取镜像
docker pull elasticsearch:7.14.0
# 建立容器并运行
# 容器名为 es,环境变量 Java 运行大小缩小一点,单机运行,挂载两个数据卷,连接网络 es,访问端口 9200,节点通信端口 9300
docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
-v es-config:/usr/share/elasticsearch/config \
--privileged \
--network es \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.14.0
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
如果你像作者一样运行时报了关于宿主机架构的问题,比如
WARNING: The requested image's platform (linux/amd64) does not match the detected host platform (linux/arm64/v8) and no specific platform was requested
只需要根据提示拉取 arm64v8 的镜像
比如作者这里就重新拉了一份
docker pull arm64v8/elasticsearch:7.14.0
然后再运行就不会出现问题了。
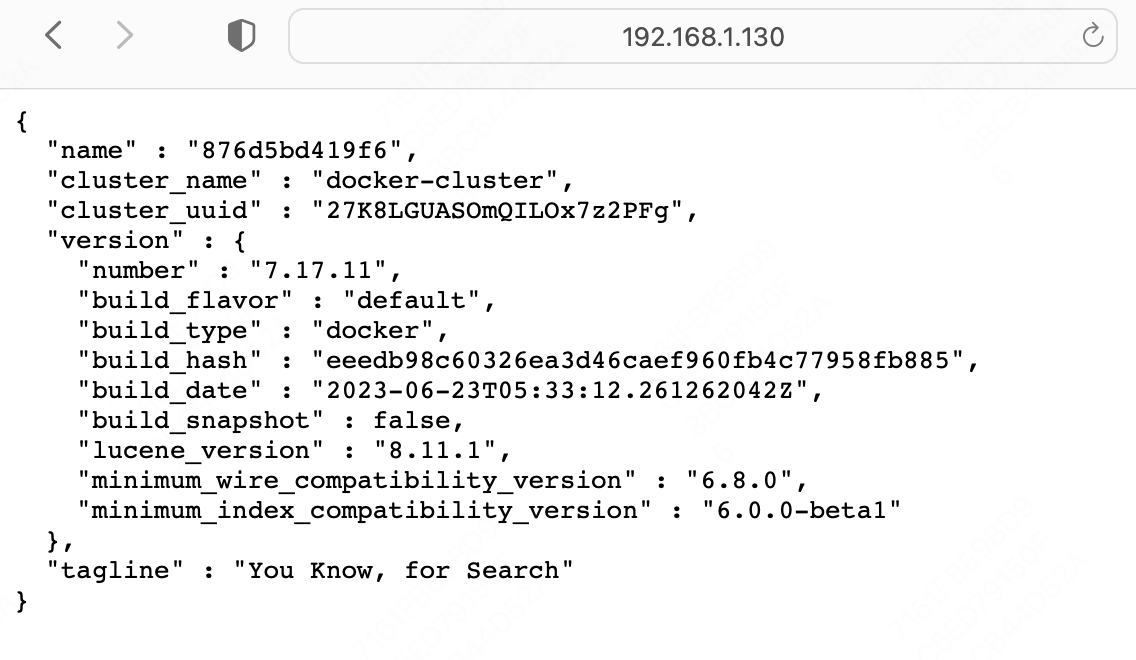
然后通过 ${宿主机ip}:9300 访问出一些 json 数据就代表运行成功了
我们也可以通过 postman 向 es 发送请求进行查询
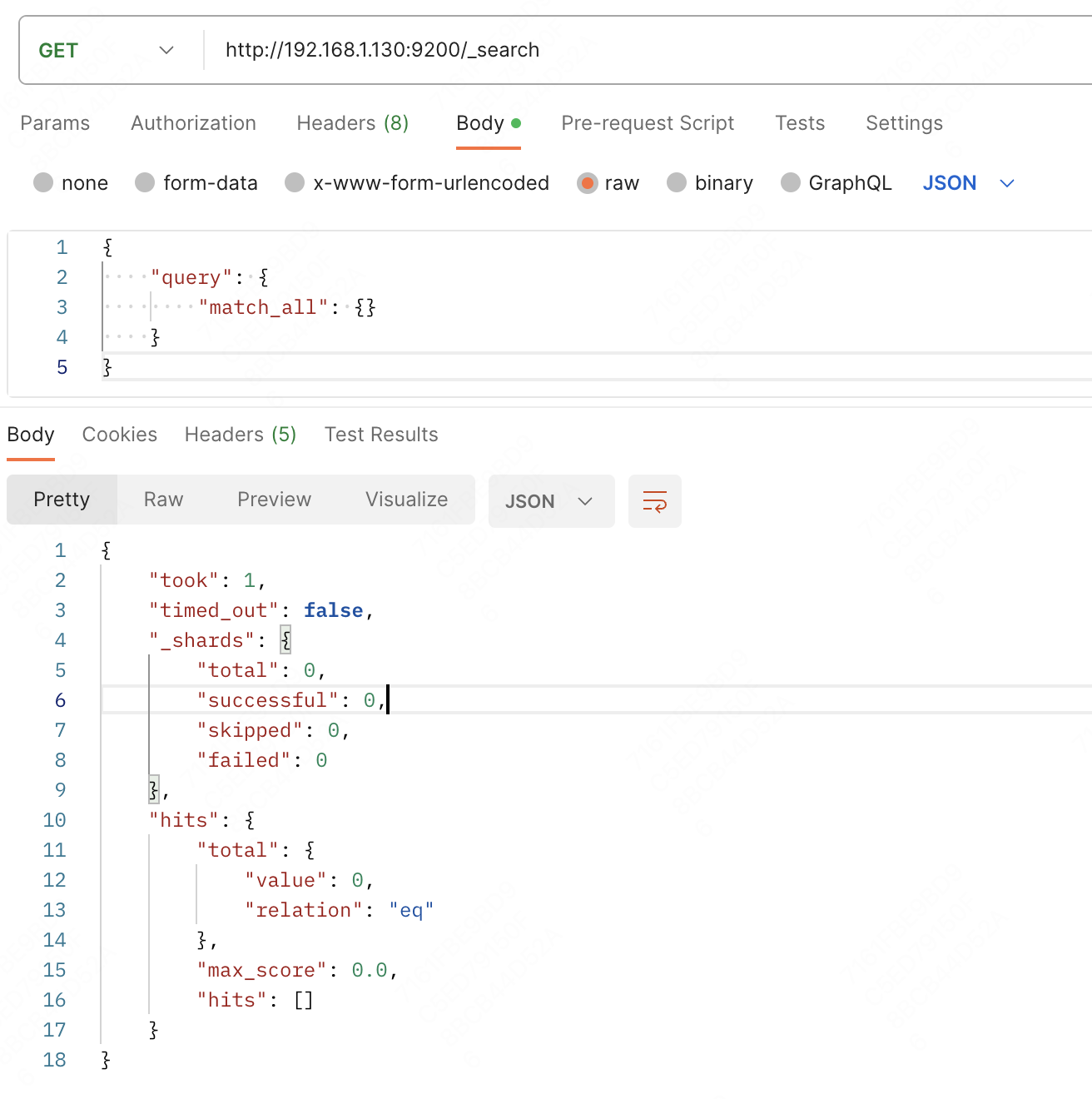
这里 match_all 就是匹配所有的意思
# 非 Docker 安装(推荐)
在 这里 (opens new window) 下载一下需要的版本。
解压下载完的压缩包后进 bin 目录下运行 elasticsearch 就行了,很方便。
# 安装JavaAPI - RestClient
RestClient是一个调测RestFulAPI的工具,可以向9200端口发送http请求并得到响应,es项目有自己的RestClient工具。
对于 es 的客户端包有 high-level 的也有 low-level 的,high-level 支持的 API 比较多
当然也有9300端口发送tcp的 spring-data-elasticsearch 包,但是官方不建议在9300端口操作,所以我们用 high-level 的客户端包
导入依赖
<!-- pom.xml -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
2
3
4
5
6
7
同时要指明我们 ES 使用的版本,这里包的版本要和它保持一致,我用的是 7.14.0 于是
<!-- pom.xml -->
<properties>
<elasticsearch.version>7.14.0</elasticsearch.version>
</properties>
2
3
4
5
然后我们要调用的工具类是 RestHighLevelClient,它的初始化和关闭方式为
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
....
// 初始化
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(
// 指定 es 的 hostname 和 http 端口
HttpHost.create("http://192.168.1.130:9200");
));
// 销毁
client.close()
2
3
4
5
6
7
8
9
10
11
12
为了后面更方便的测试学习功能,将 client 放到配置类中设置为 Bean
public class ESIndexTest {
private RestHighLevelClient client;
@BeforeEach
void setUp () {
this.client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.1.130:9200")
));
}
@AfterEach
void close () throws IOException {
this.client.close();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
可能有的小伙伴在 HttpHost.create 会报错
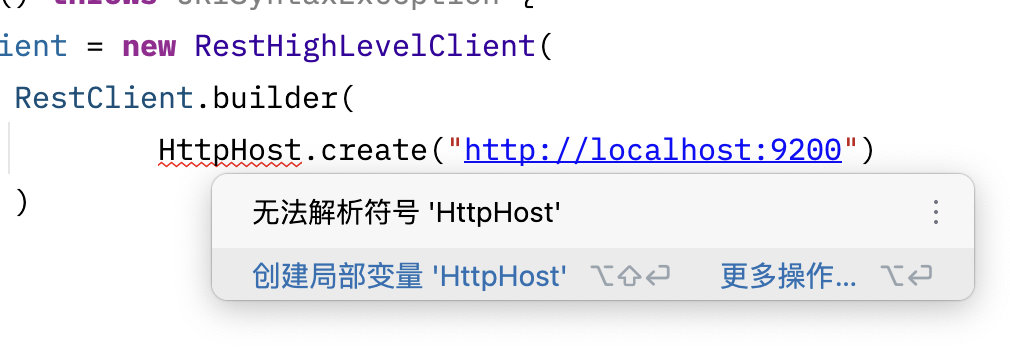
这里是因为 java 默认 4.4.5 版本的 httpcore 依赖,手动引入一个 4.4.6 版本的即可
<!-- pom.xml -->
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpcore</artifactId>
<version>4.4.6</version>
</dependency>
2
3
4
5
6
7