深度分页
# 什么是深度分页
深度分页 指的是在排序的情况下,查询很“深”(大页码)的页面数据。
首先要知道分页发生时,如查询排名在第 10000 条到第 10010 的文档,ES 需要经历两步:
- 排序(堆维护)获取到前 10010 个文档
- 分页返回处在 [10000, 10010] 的结果
这很好理解,要得到排名在 [a,b] 区间的元素,那至少要排了才能给吧,所以一次分页的复杂度考量的是 b 的大小。
考虑一下分布式,ES 存在 5 个分片,这个时候 ES 的步骤为:
- 每个分片都要取出排序后前 10010 个文档
- 将这 50050 个文档排序(堆维护)出前 10010 个文档
- 分页返回处在 [10000, 10010] 的结果
每个分片都要拿出前 10010 个元素是因为文档在分布式内分发的时候考虑负载均衡,是比较均匀地放置的。而对于排序规则,可能一个分片内的数据就算拿完了排名也不一定在前 10010 位。
而一个分片排序后的第 10011 位是一定不在综合前 10010 位的,毕竟比它靠前的都有 10010 个了,故每个分片都要排出前 10010 个元素。
# 负面影响
因为这些排序都是在堆中进行的,因此深度分页可能会导致 OOM 或者 FGC 的产生,对机器内存、性能、系统响应速度都产生较大压力。
max_result_window 参数
之前说过 ES 的分页复杂度应考量区间右端点的大小,而 ES 也给了右端点的限制 max_result_window,这个参数默认是 10000,也就是说当右端点超过 max_result_window 时,是会被拒绝的。
这个参数是可以调的,具体的设置不应是业务要查到哪了就定到哪,而是应该结合数据量、内存大小进行设置的。
又不想一次响应或者在本地内存中存储太大的数据,又想把大量排序后的数据都处理一下,从系统层次(本篇不关心业务上怎么提供数据给用户)来讲,最常见的做法就是分批,而 ES 对于分批获取的方式即为 “滚动查询”,对于排序好的数据每次滚动一段进行响应,就满足上面说的需求了,具体滚动策略有下面几种。
# 解决方案1:Scroll
Scroll 查询的本质是在第一次查询时保存一个快照,第一次 scroll 查询后返回一个 id,之后就拿着这个 id 进行查询直到最后没有数据或者 id 超时为止。
这种快照查询的优点在于查询过程中即使数据变动,也不会对查询结果有任何影响,存在较强的一致性,但这也有可能会成为缺点,因为实时性较差。
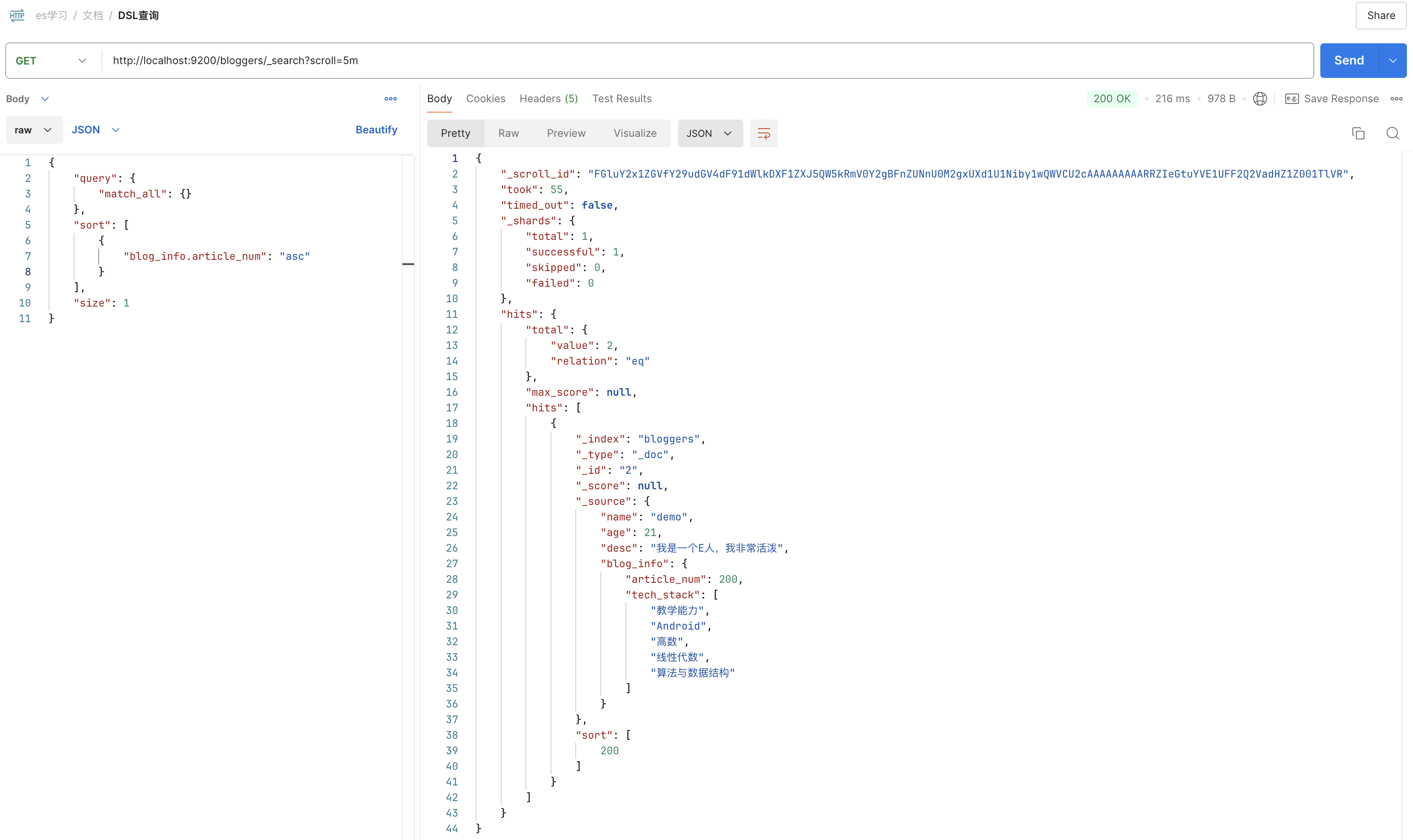
使用方式为第一次调用 GET /${索引名}/_search?scroll=${索引id超时时间} 然后请求体内包含查询条件、排序规则、分页大小等...,如下在我创建的 bloggers 索引内查询
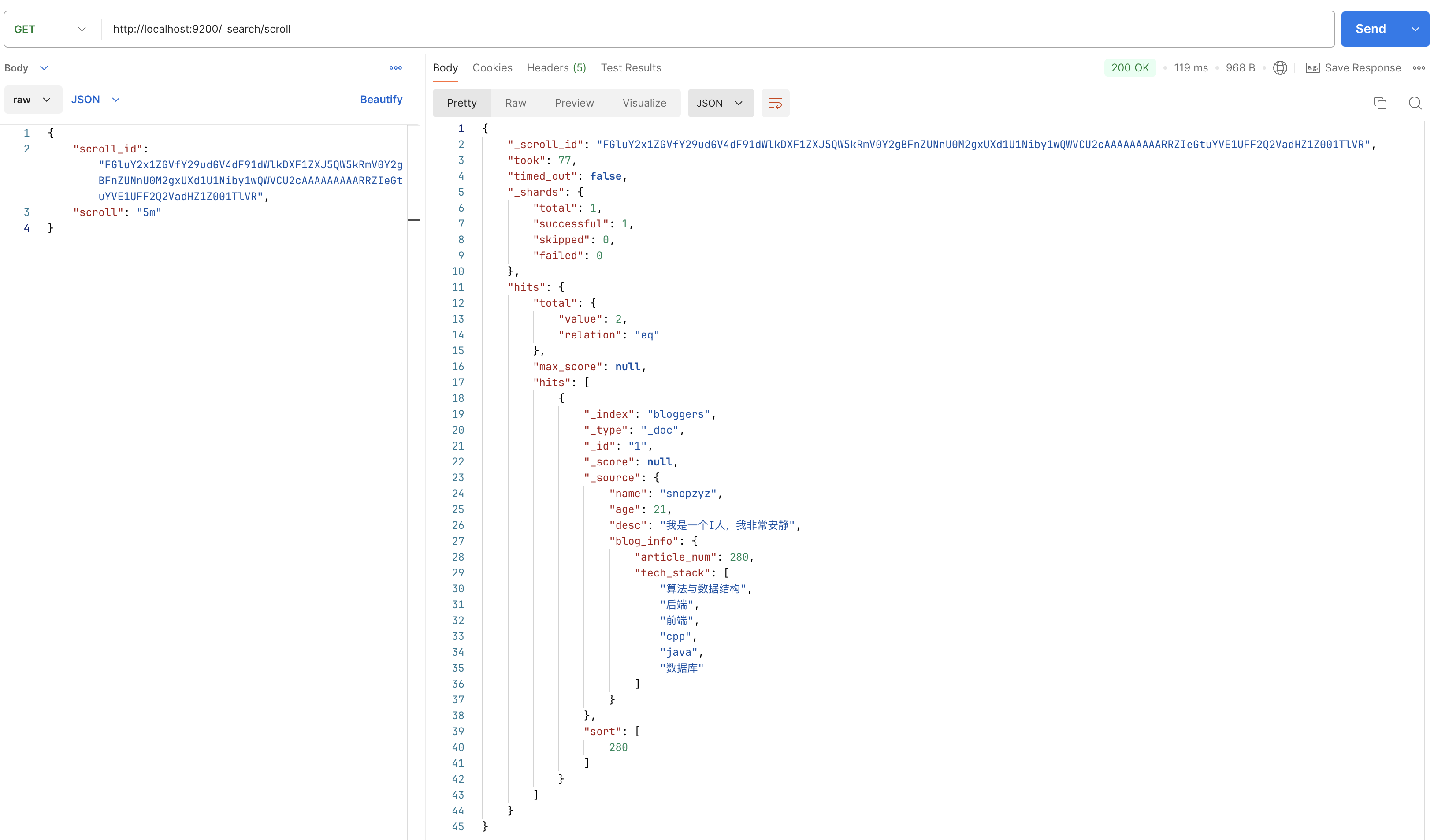
在拿到响应 json 根路径下的 _scroll_id 后,查询方式要发生更改,变为调用 GET /_search/scroll ,在请求体内传 scroll_id 和超时时间 scroll,如下
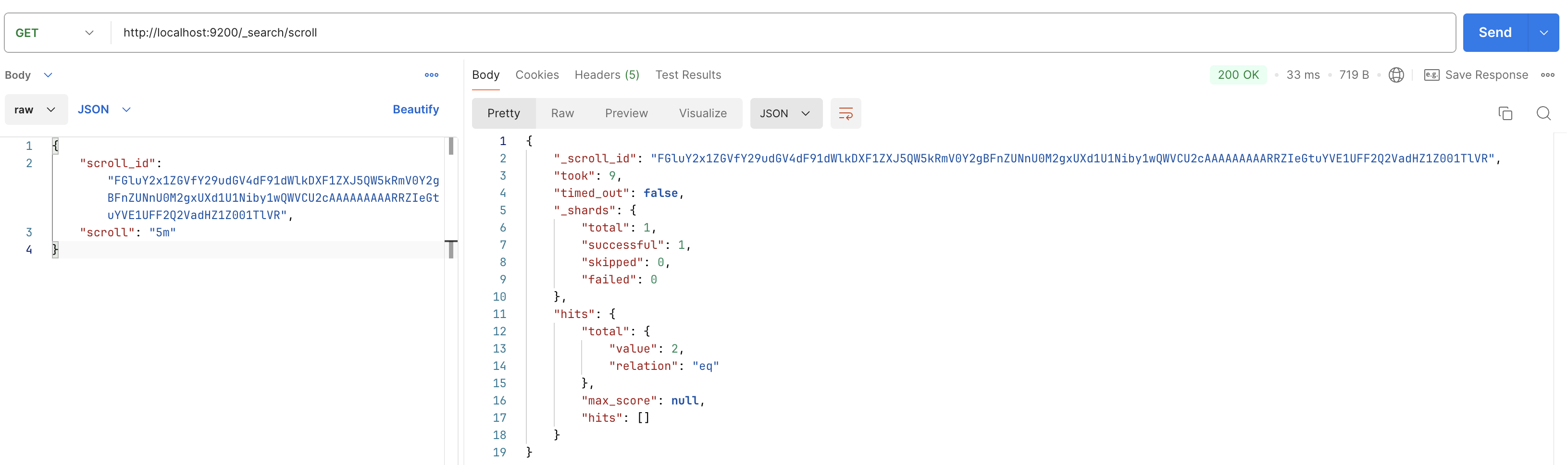
之后的查询便都一样了,因为我这边索引内只有两条数据,因此这第三次查询会是空结果,之后的也会是空的
快照清理
scroll 上下文快照是很占用系统资源的,因此在超时之前查询完最好可以手动清理,ES 也提供了两种清理请求:
- 清除指定 scroll_id:
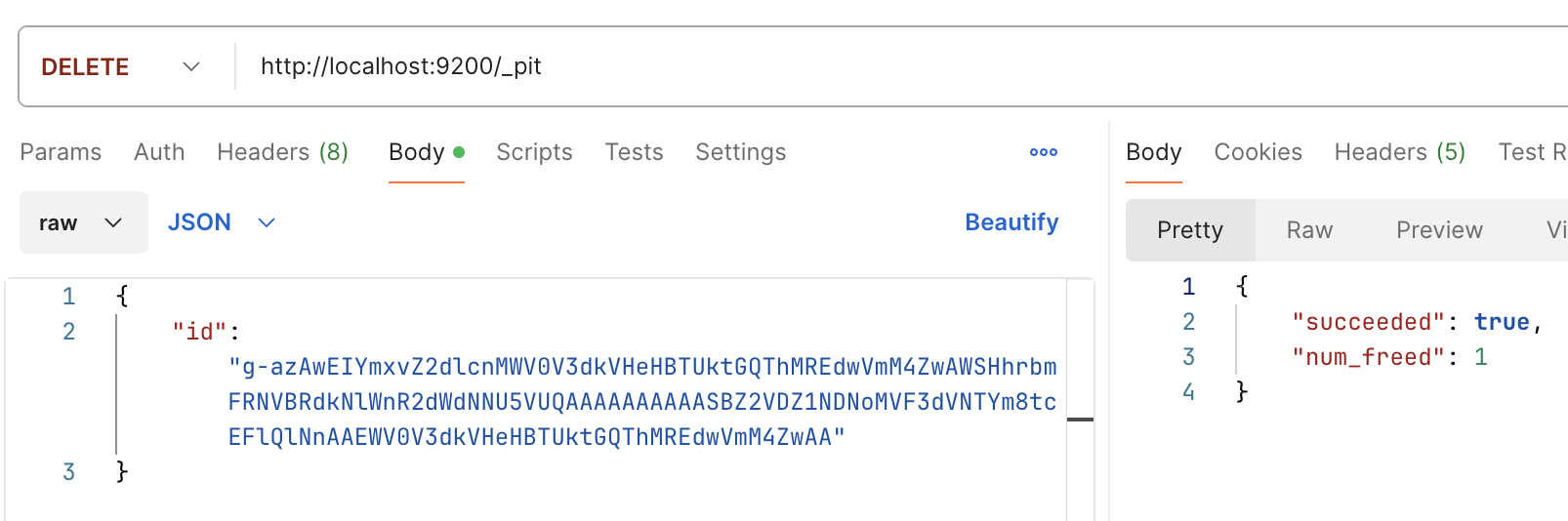
DELETE /_search/scroll/${scroll_id} - 清除所有快照:
DELETE /_search/scroll/_all
scroll 适合导出场景
# 解决方案2:Search After
search after 采用实时的请求形式,只需要每次提交上次排序值(该排序值最好唯一),本次请求处理会根据提交的排序值获取它后面的 size 个元素。
相比于 scroll 查询,不用维护上下文且实时性会更强,且每次查询可以采用不同的查询语法,相比 scroll 查询更加灵活。
但新数据或者改动的数据可能会对查询结果产生影响,故需要更细致合理的业务操作来避免。
使用方式为第一次按正常查询构造 GET /${索引名}/_search
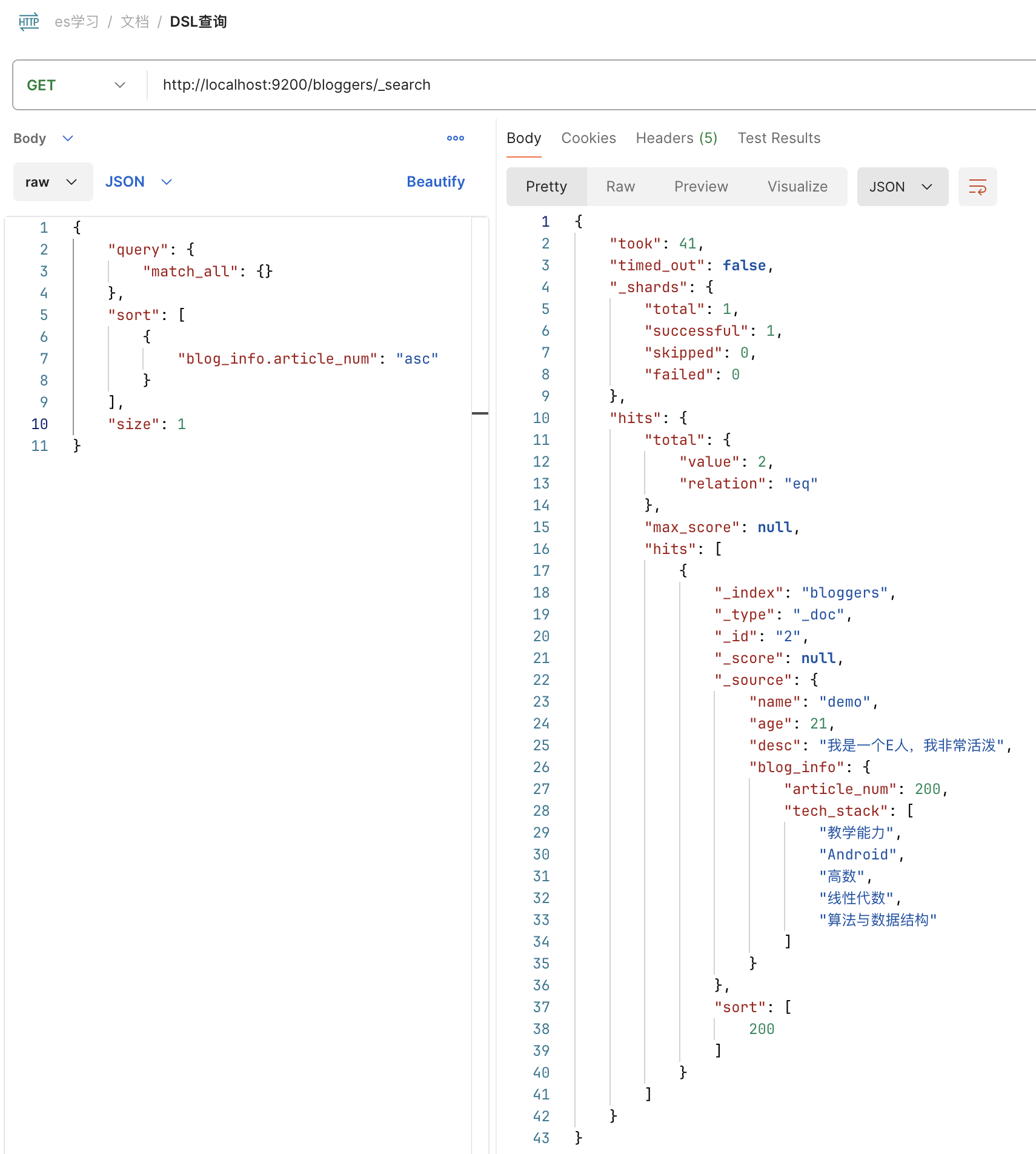
而第二次要在请求内添加字段 search_after 内部按照 sort 字段内的顺序,填充上次查询出来的结果(其实就是按照 hits.hits 最后一条的 sort 字段写就行)
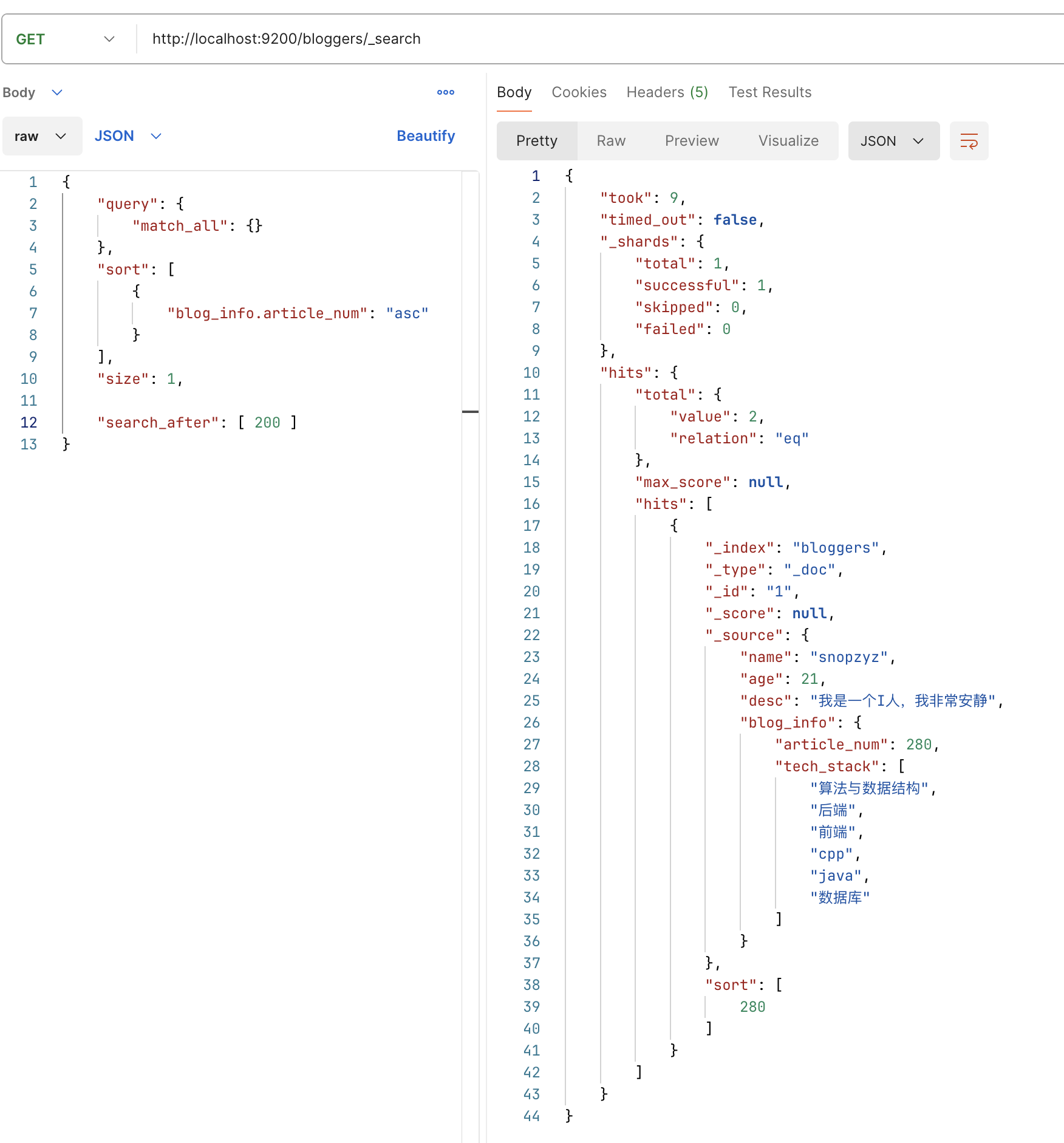
若排序值不唯一
若排序值不唯一,如按 key 排序查询,有三个文档(id=1,id=2,id=3,id=4) key 都为 3,一次查询后刚好查到 id=2 的文档, sort 值为 3。
此时下次查询设定 search_after 为 3,那么查询结果
- 可能从 id=2 开始,发生重复
- 可能从 id=4 开始,发生缺失
为应对这种,从业务处理层面可以在排序内多添加一个唯一 uuid 作为最后一个关键字(这也是官方推荐的做法)
而其实数据重复和缺失的情况不止出现在排序值重复上,还可能因数据更新导致顺序变化导致。如对 key 升序查询,有四个文档 (id=0,key=0),(id=1,key=1),(id=2,key=2),(id=3,key=3)。
此时滚动查询 size 为 1,查完 id=2 后 search_after=2,若此时 (id=0,key=0) 的文档将 key 更新为 4,那么在后面的查询会再查询出来一次该文档。
这是从前往后更新的情况发生重复,而对于从后往前更新,则同理发生缺失。
为了针对这种问题,ES 引入了 PIT 查询。
search_after 适合分页查询场景
# 优化:PIT(point in time)
针对 search_after 的实时性问题,ES (v7.10 +) 通过保留索引当前状态(依旧类似于快照),来保证 search_after 每次查询都是一样的内容。
这种方案结合了 scroll 一致性的优点和 search_after 的灵活性优点,虽然会带上 scroll 的耗费资源的缺点。
查询首先创建一个 PIT 时间点 POST /${索引名}/_pit?keep_alive=${PIT超时时长}
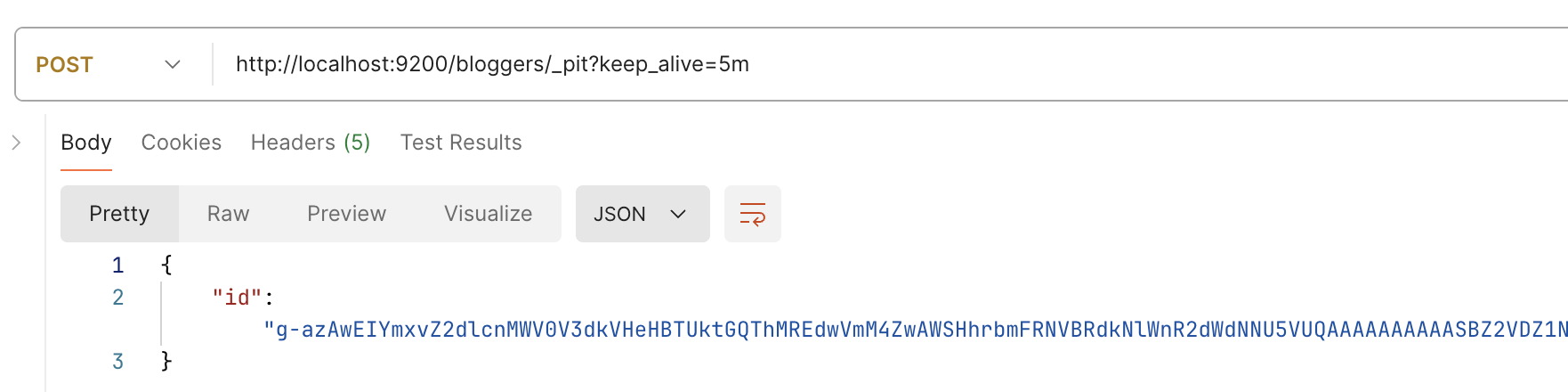
拿到 id 后,填写进分页查询中(注意不再填写索引名了,打 PIT 的时候就已经保存索引了)
GET /_search
{
/*
* search_after 语法
*/
"pit": {
"id": "(String) ${上一步获取的pit_id}",
"keep_alive": "$(String) ${超时时间}"
}
}
2
3
4
5
6
7
8
9
10
11
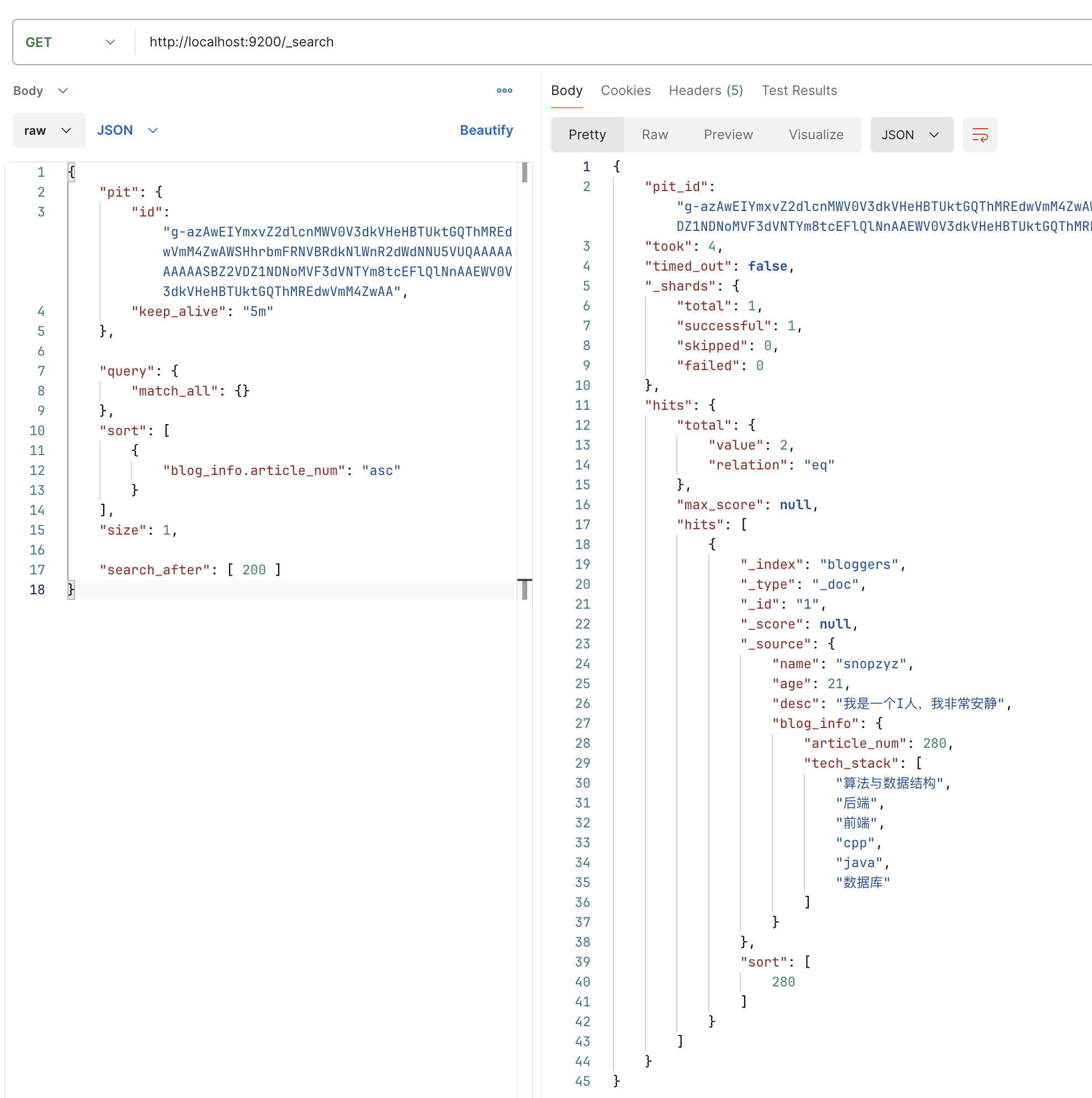
如我根据刚刚创建的 pit_id 进行我之前的 search_after 查询。
而相对的,PIT 也有自己的释放方式:
DELETE /_pit
{
"id": "${PIT_ID}"
}
2
3
4