拼音分词器-自动补全
在各种大型平台的输入搜索框中,都能做到在英文输入法,随手打了个 “wx” 就能弹出 “微信” 或者其他的相关链接,这种识别方法就是拼音识别。
而拼音识别自然要有其对应的插件 “拼音分词器”。
安装与下载
下载在 这里 (opens new window),找到你安装 es 的对应版本下载即可。
安装不再叙述了,流程和 ik 分词器的流程一样,不了解的可以看 上面这一篇。
而要使用这个分词器,肯定要先拆词,再转化拼音,所以 ik 分词器还是不能丢掉。
而要组合两种分词器,就不得不提到分词器的自定义了。
# 自定义分词器
分词器的组成结构
既然要学习两种分词器的搭配,就要先了解他们是怎么协调运作的。
分词器组成与流程步骤有三部分:
- character filters:对文本进行处理,如按规则替换子串。
- tokenizer:对文本切割、或类似于keyword类型的不分词。
- tokenizer filter:对结果的词条列表处理,如转化为拼音、大小写切换...。
从它们的定义可以看出,ik 分词器位于 tokenizer,拼音分词器位于 tokenizer filter。
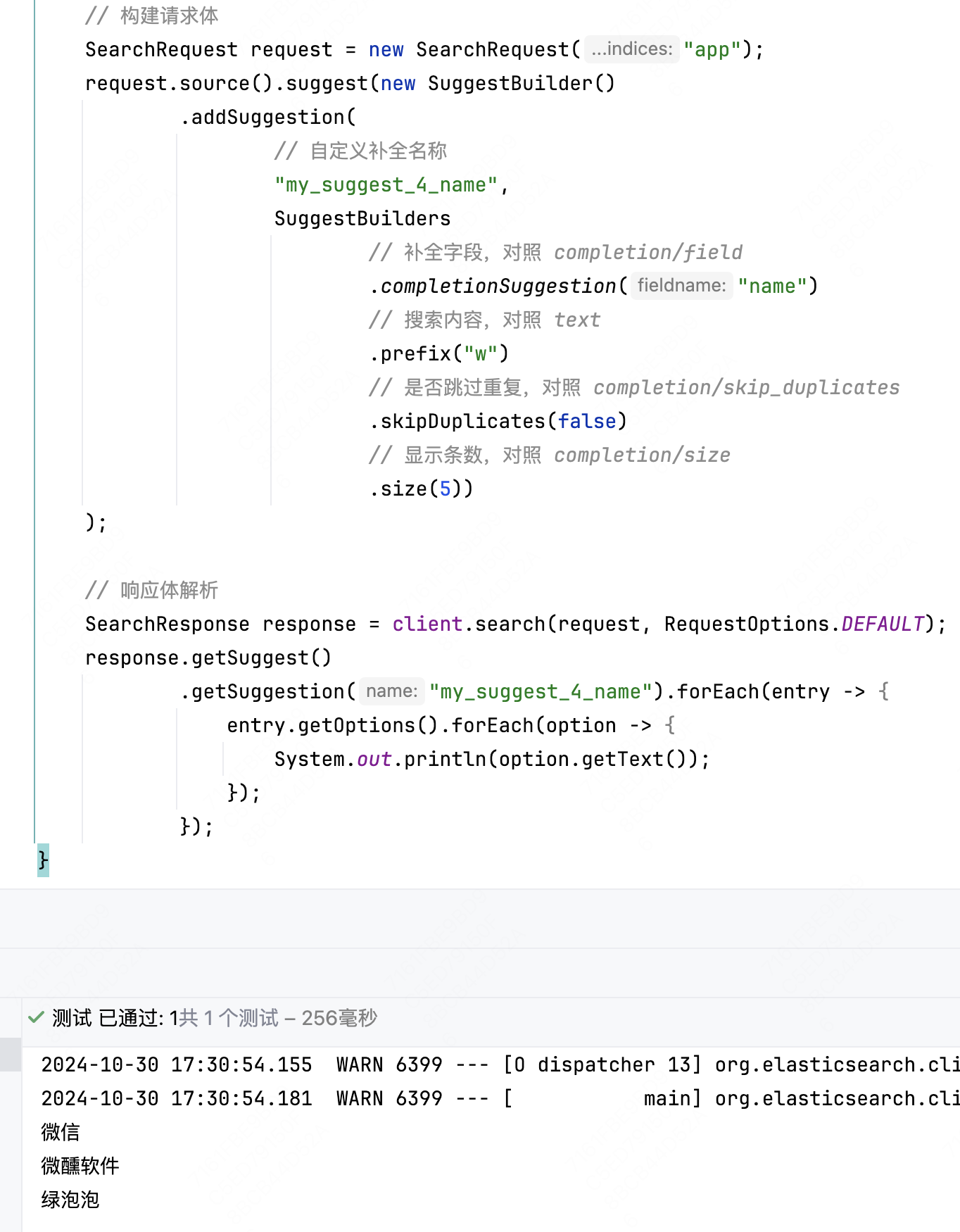
自定义分词器在创建索引的时候使用,和 mappings 位于同级新增一个字段 settings。
{
"settings": {
"analysis": {
// 自定义分词器,用来使用自定义的分词器三要素的
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_max_word",
"filter": ["my_pinyin"],
"char_filter": ["my_mapping_filter"]
}
},
// 自定义 tokenizer filter
"filter": {
"my_pinyin": {
"type": "pinyin", // 过滤器类型,使用拼音分词器,下面是一些拼音分词器的配置
"keep_full_pinyin": true, // 分词结果存在每个汉字的全拼,"刘德华" -> ["liu", "de", "hua"]
"keep_joined_full_pinyin": true, // 分词结果有整体的全拼,"刘德华" -> "liudehua"
"keep_original": true, // 保留原始的输入,"刘德华" -> "刘德华"
"limit_first_letter_length": 4, // 只显示首字母的前多少个,"中华人民共和国" -> "zhrm"
"remove_duplicated_term": true, // 移除重复词条
"none_chinese_pinyin_tokenize": true // 将非中文也按照可能的拼音分词
}
},
// 自定义 character filters
"char_filter": {
"my_mapping_filter": {
"type": "mapping",
"mappings": [
":)=>开心",
":(=>难过"
]
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
而它在 mappings 中对应字段使用它的方法如下:
{
"mappings": {
"properties": {
"字段名": {
"type": "text",
"analyzer": "my_analyzer",
"search_analyzer": "ik_smart"
}
}
}
}
2
3
4
5
6
7
8
9
10
11
注意这里加了个搜索分词器,这就是 es 对搜索的文本进行分词的工具,而且是不建议使用拼音分词器的。
比如搜索了 "你好",拼音分词器分成了 "nh",此时如果倒排索引内有个 "男孩" 并且也被拼音分词了,可能就会被匹配上了,不过如果有同音词的搜索需求,也可以用的。
下面就新建一个名为 app 的索引试一试这个功能(这里梗一下,给微信加一个绿泡泡的别名)。
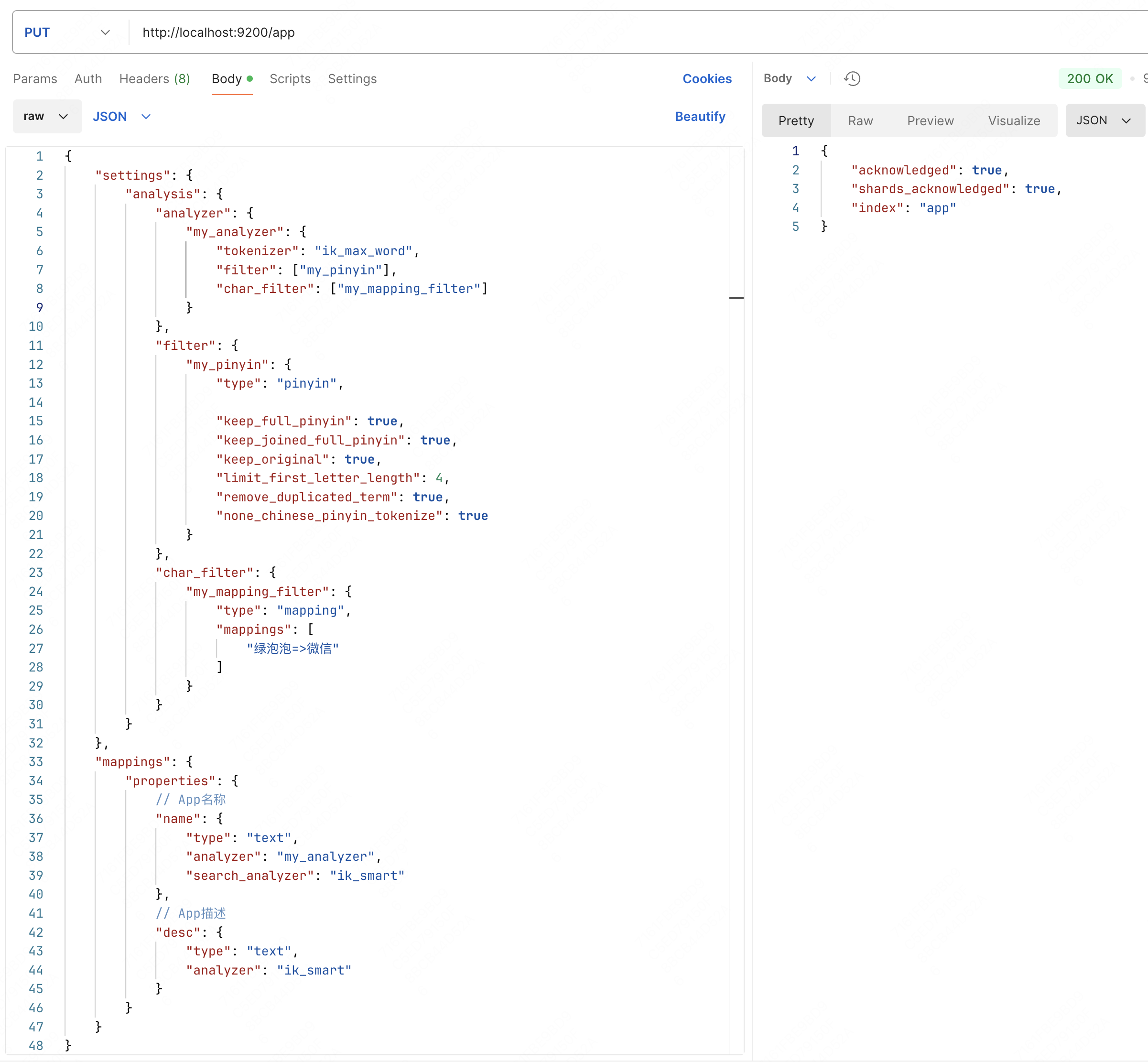
并新增一些对应的文档
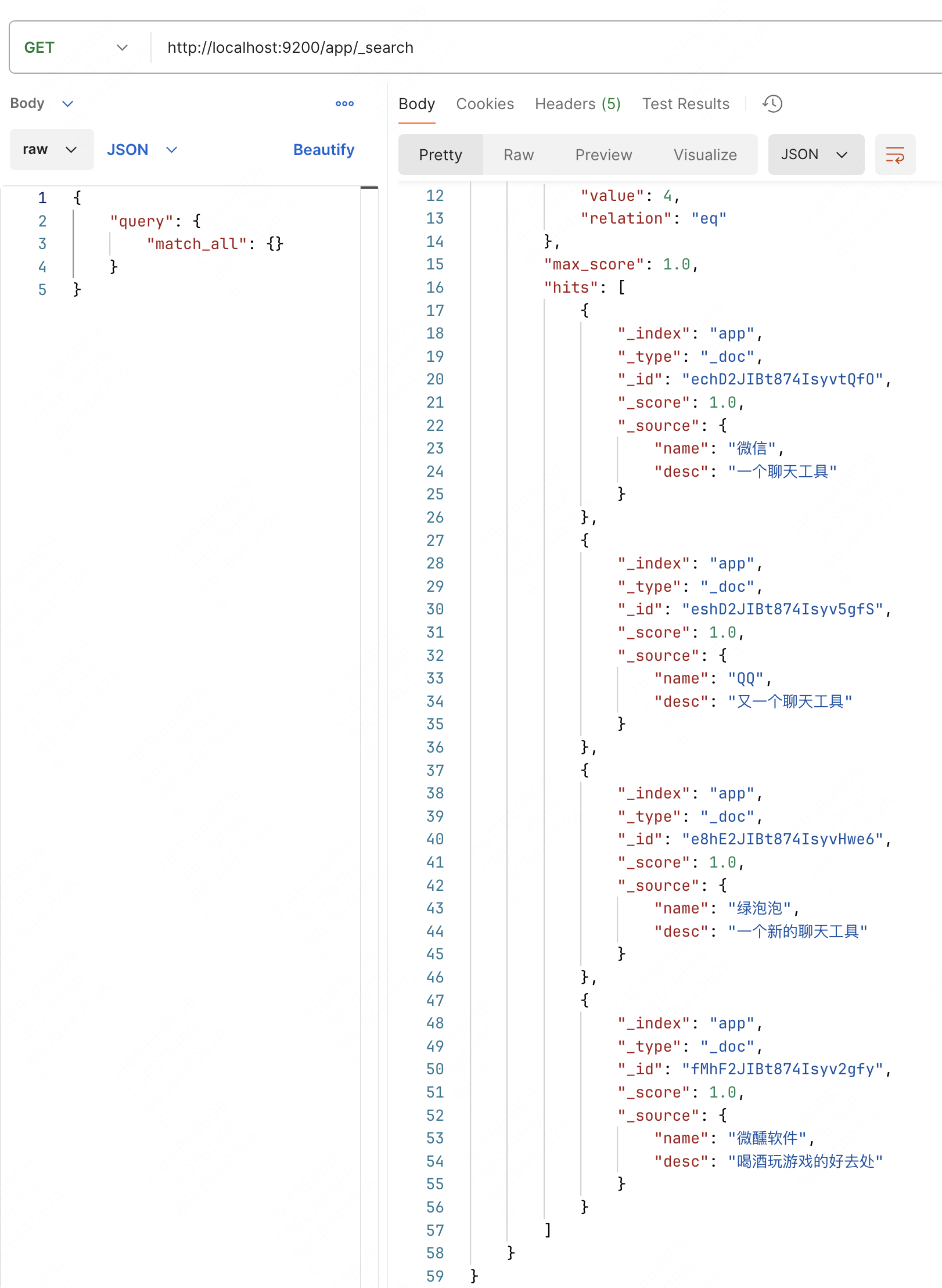
# 自动补全查询
自动补全查询又叫做 suggest 查询。
如果要支持自动补全查询的话,首先文档字段定义时,应被设置为 "type": "completion",对应调整上面设置的 name 字段。
查询模板如下:
GET /${索引名}/_search
{
"suggest": {
"${自定义补全查询名称}": {
"text": ${(String) 查询内容},
"completion": {
"field": ${(String) 被匹配的字段},
"skip_duplicates": ${(Boolean) 是否跳过重复选项},
"size": ${(Number) 显示数量}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
比如我要通过 "w" 查询 "微信"、"微醺软件"、"绿泡泡"(我们在前面设定了它就是微信) 这三个 App
注意
IK 分词器会把 “微信” 割为 ["微", "信"],要注意添加自定义词条。
关于添加方式请看 这里
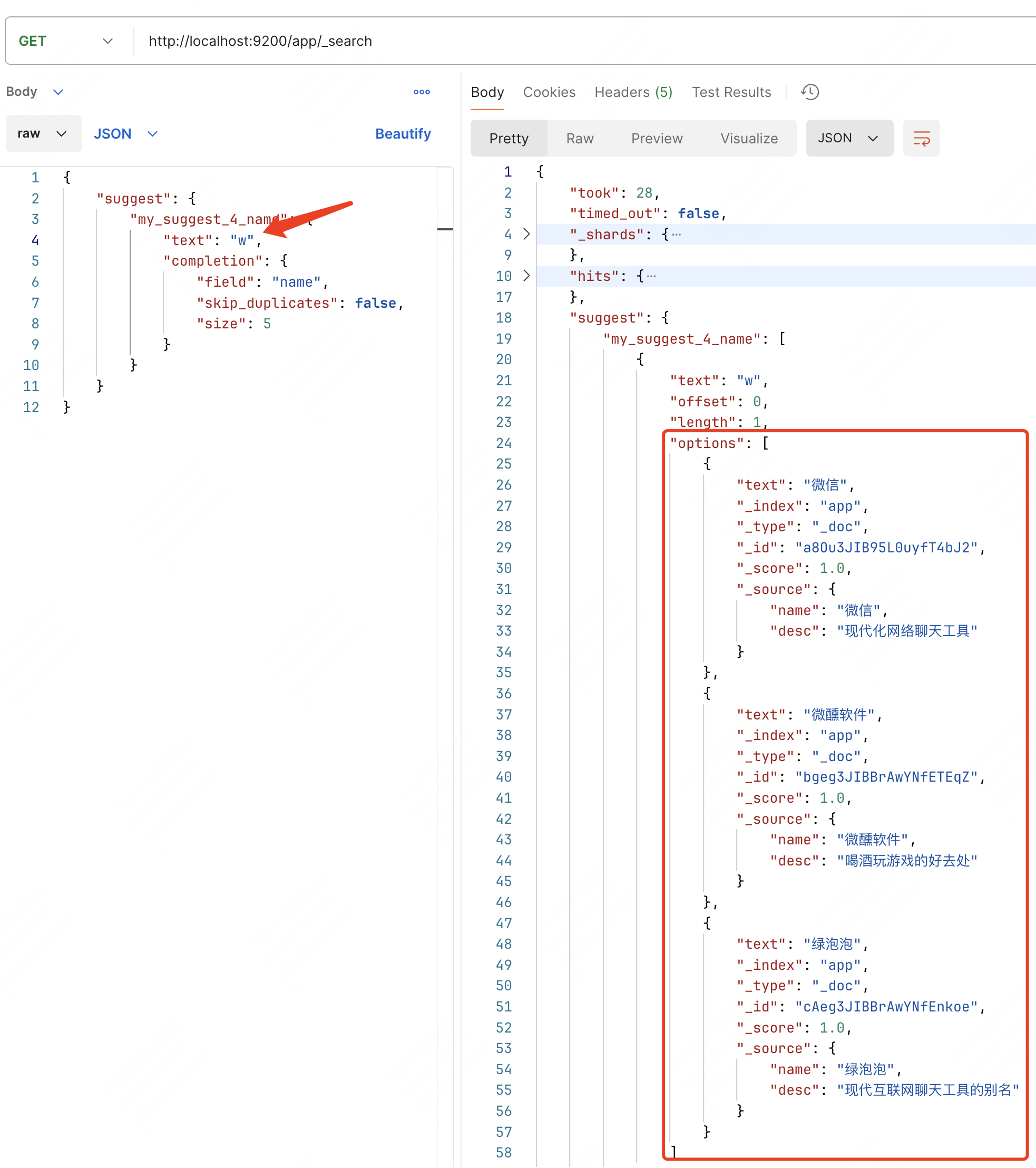
下面当然还要知道通过代码完成补全的方式,对于请求来说有一点点不适用这里提到的 RestClient 方法共性,会细致列出 Suggestion 的对象构造方式。
这里也是照着前面的 http 请求完成的内容来查询的。
// 构建请求体
SearchRequest request = new SearchRequest("app");
request.source().suggest(new SuggestBuilder()
.addSuggestion(
// 自定义补全名称
"my_suggest_4_name",
SuggestBuilders
// 补全字段,对照 completion/field
.completionSuggestion("name")
// 搜索内容,对照 text
.prefix("w")
// 是否跳过重复,对照 completion/skip_duplicates
.skipDuplicates(false)
// 显示条数,对照 completion/size
.size(5))
);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
至于结果解析就很简单了,可以按照共性去推的。
在 /suggest 下找到名为 my_suggest_4_name 的自定义补全(它对应的值是个array),然后遍历值拿到每个值的 options 再进行遍历,取每一个结果的 text 就可以验证代码了。
下面注释是带着走应对应的左值的 json 路径的。
// 响应体解析
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// /suggest
response.getSuggest()
// /suggest/my_suggest_4_name
.getSuggestion("my_suggest_4_name")
// /suggest/my_suggest_4_name/[i]
.forEach(entry -> {
// /suggest/my_suggest_4_name/[i]/options
entry.getOptions()
// /suggest/my_suggest_4_name/[i]/options/[j]
.forEach(option -> {
// /suggest/my_suggest_4_name/[i]/options/[j]/text
System.out.println(option.getText());
});
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
这里是打印结果