文档高级 DSL 检索
企业里面常用高级的检索方式来更精确地应对复杂场景,这种检索概括一下往往是这样的模板:
GET /${索引名}/_search
{
"query": {
"${查询类型}": {
"${查询条件}": "${条件值}"
}
}
}
2
3
4
5
6
7
8
查询类型非常多,有如 bool、match_query、match_all、term...,(后面会讲解用法)
这里先给出一个简单的 match_all 查询所有的小示例讲解一下用法和响应
{
"query": {
"match_all": {}
},
"from": 0,
"size": 100
}
2
3
4
5
6
7
这个请求是查询所有然后做了一个分页,看一下响应
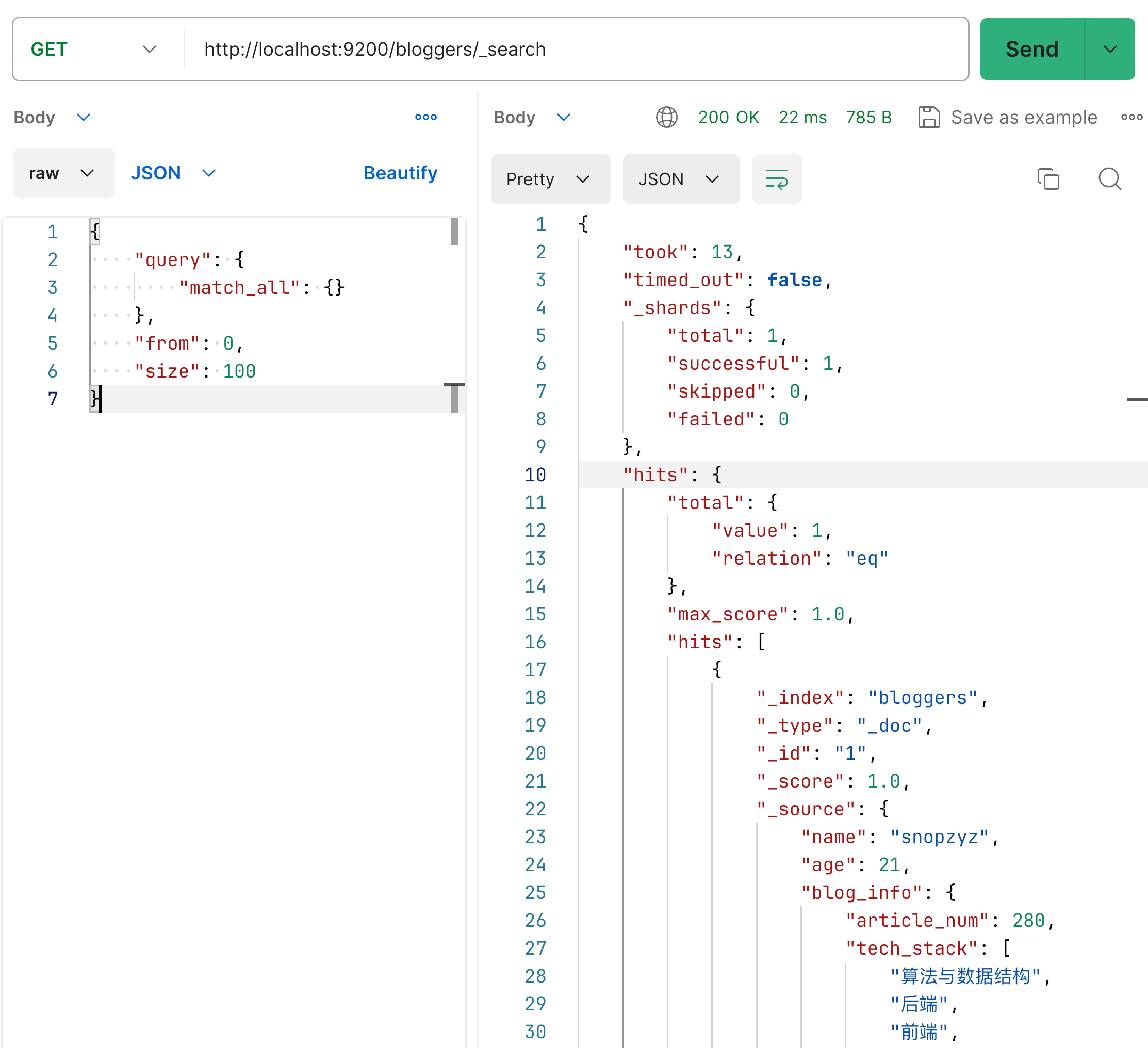
其中拆解来看主要是如下一些信息,其中涉及到一些 “分片” 的东西,这个此时无关要讲的内容 后面 会说的。
{
"took": "耗时(ms)",
"timed_out": "是否超时",
// 分片信息
"_shards": {
"total": "总分片数",
"successful": "成功的分片数",
"skipped": "被跳过的分片数",
"failed": "失败的分片数"
},
// 查询结果元数据
"hits": {
"total": {
"value": "匹配的文档总数(分页前)",
"relation": "表示实际匹配文档数与value的关系,通常是eq(等于)或者gte(大于等于)"
},
// 积分匹配制
"max_score": "最高相关性积分",
"hits": "分页后的数据内容(列表)"
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
想了解积分匹配的小伙伴请前往 检索下的相关性得分。
再抽出来 hits.hits 说说
{
"_index": "文档所在索引名称",
"_type": "文档类型,v7.x以及更高版本弃用了,通常都是 _doc",
"_id": "文档id",
"_score": "相关性得分",
"_source": "实际文档数据"
}
2
3
4
5
6
7
从代码角度使用 SearchRequest 和 SearchResponse 作为入参请求(初始化时放入索引名)和出参响应,而调用时采用 client.search(...)
SearchRequest.source().query(...) 方法内填充我们具体的查询内容 QueryBuilder。
# 全文检索
全文检索是根据指定的字段和值,将值分词后去倒排索引库中检索。
# match
对一个建立了倒排索引的字段进行检索。
内部结构模板为
"match": {
"${字段名}": "${匹配值}"
}
2
3
作者在 索引库操作 里面建的 bloggers,其中刚好有个 blog_info.tech_stack 具有倒排索引,那就拿这个做演示。
可以看到 match 检索的方式是内部 kv 表示的是 “被检索字段”: “检索词条”
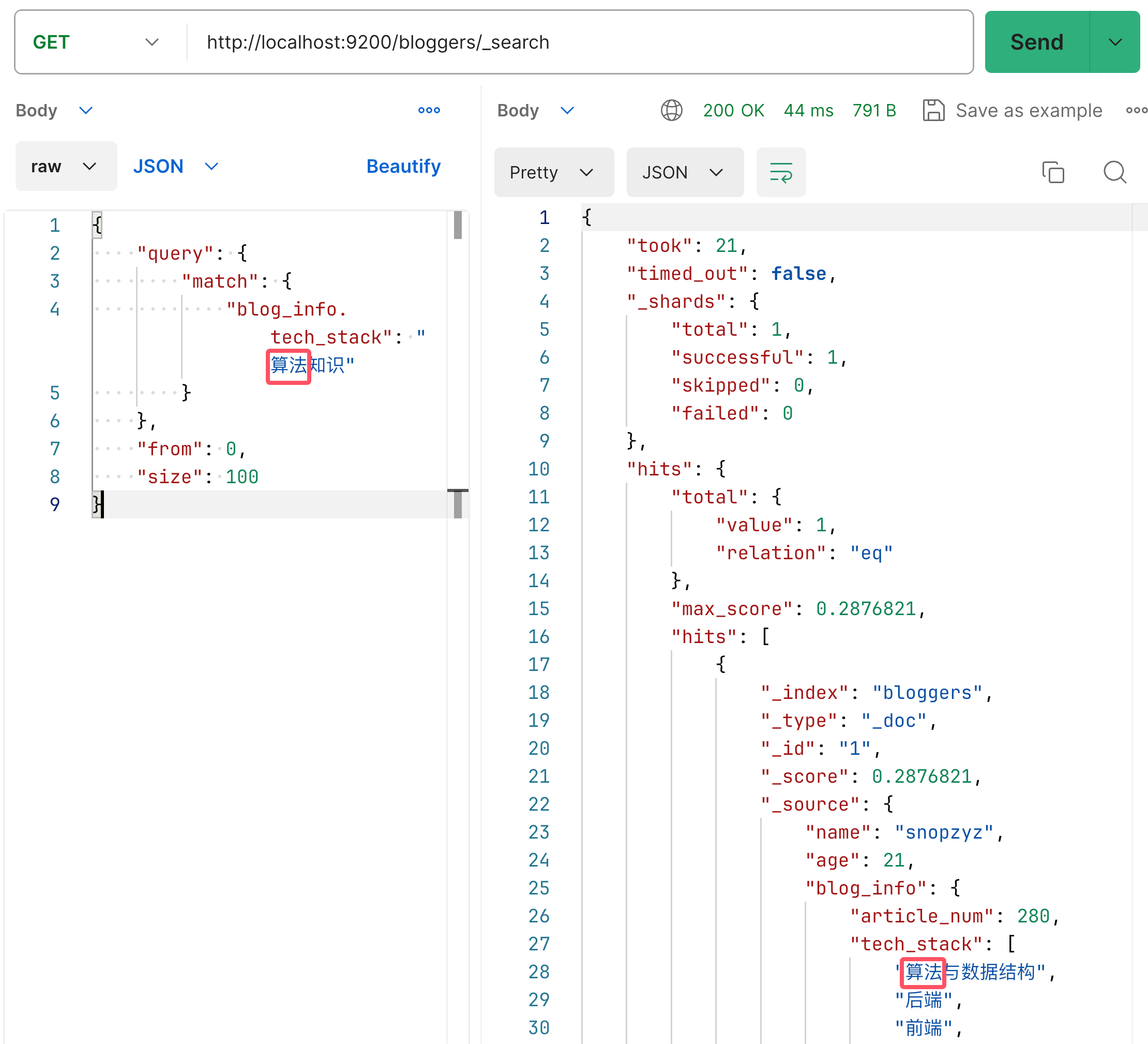
可以看到查询出来了,相关性得分比较低因为匹配度较低。
而且值得称赞的是这个匹配度是倒序排序的,很贴合正常的词条搜索机制。
代码实现的话 match_all,对应就是 QueryBuilders.matchAllQuery()
而解析也跟 DSL 查询一样有 hits,使用 response.getHits(),对应就是
// 构建请求体
SearchRequest request = new SearchRequest("bloggers");
QueryBuilder queryBuilder = QueryBuilders.matchAllQuery();
request.source().query(queryBuilder);
// 调用获取响应
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 解析响应结果
response.getHits().forEach(hit -> {
System.out.println(hit.getSourceAsString());
});
2
3
4
5
6
7
8
9
10
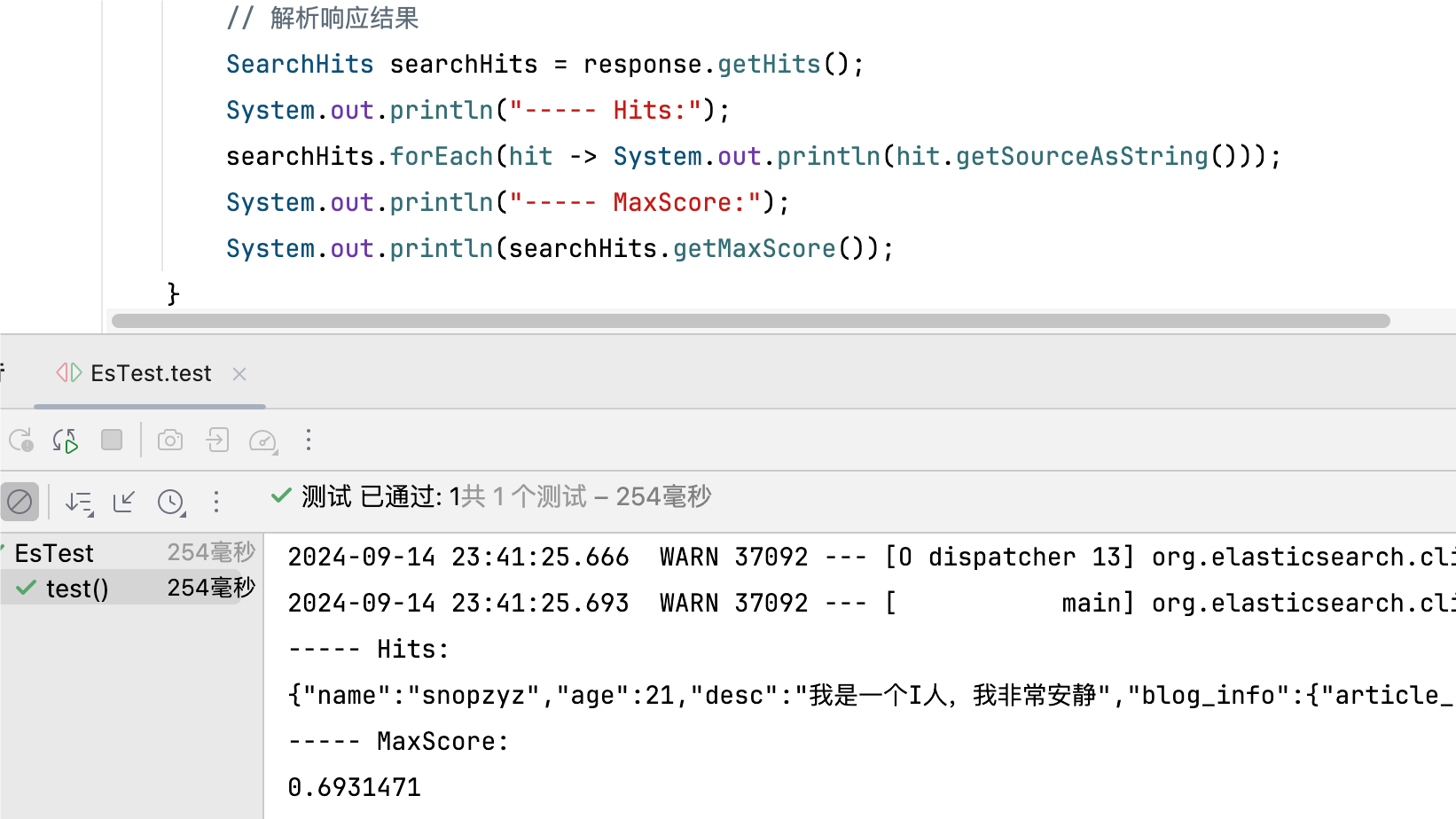
response.getHits() 对应的是 SearchHits 类型的变量,而它给出的得到的结果在通过 http 查询中得到的响应体也都是能 get 到的。
代码运行结果如此
而针对字段的 match 使用 QueryBuilders.matchQuery("${字段名}", "${查询值}")
// 构建请求体
...
QueryBuilder queryBuilder = QueryBuilders.matchQuery("name", "snopzyz");
// 调用...
...
2
3
4
5
# multi_match
会影响性能不建议用,这里简单说明一下请求结构
"multi_match": {
"query": "${匹配值}",
"fields": [
"${匹配字段1}",
"${匹配字段2}",
...
]
}
2
3
4
5
6
7
8
做个示例,这里 name 本来是 keyword,我们假装它不是,分词建倒排索引了
{
"multi_match": {
"query": "snopzyz的算法知识",
"fields": [
"name",
"blog_info.tech_stack"
]
}
}
2
3
4
5
6
7
8
9
优化使用
想使用多个字段检索其实可以在插入的时候把几个字段组织一下合并为一个字段,如这里可以新增字段 "author_like": "${name}_${blog_info.tech_stack.join('_')}",那么该文档会变为。
{...
"author_like": "snopzyz_算法与数据结构_后端_前端_cpp_java_数据库"
...}
2
3
然后 match 检索就行
# 精确查询
不进行分词,一般是对 bool、keyword、数值等类型字段查询。
代码和前面类似采用 SearchRequest 的类做请求体,这里只说下 QueryBuilder
# term
根据值进行精准查询,要匹配上才行。
具体使用查询类型为 term,内部为
"query": {
"term": {
"${字段名}": {
"value": "${匹配值}"
}
}
}
2
3
4
5
6
7
索引库操作 里面建的 bloggers 有个 name 是 keyword,我们查询一下它等于 snopzyz 的文档。
使用示例如下
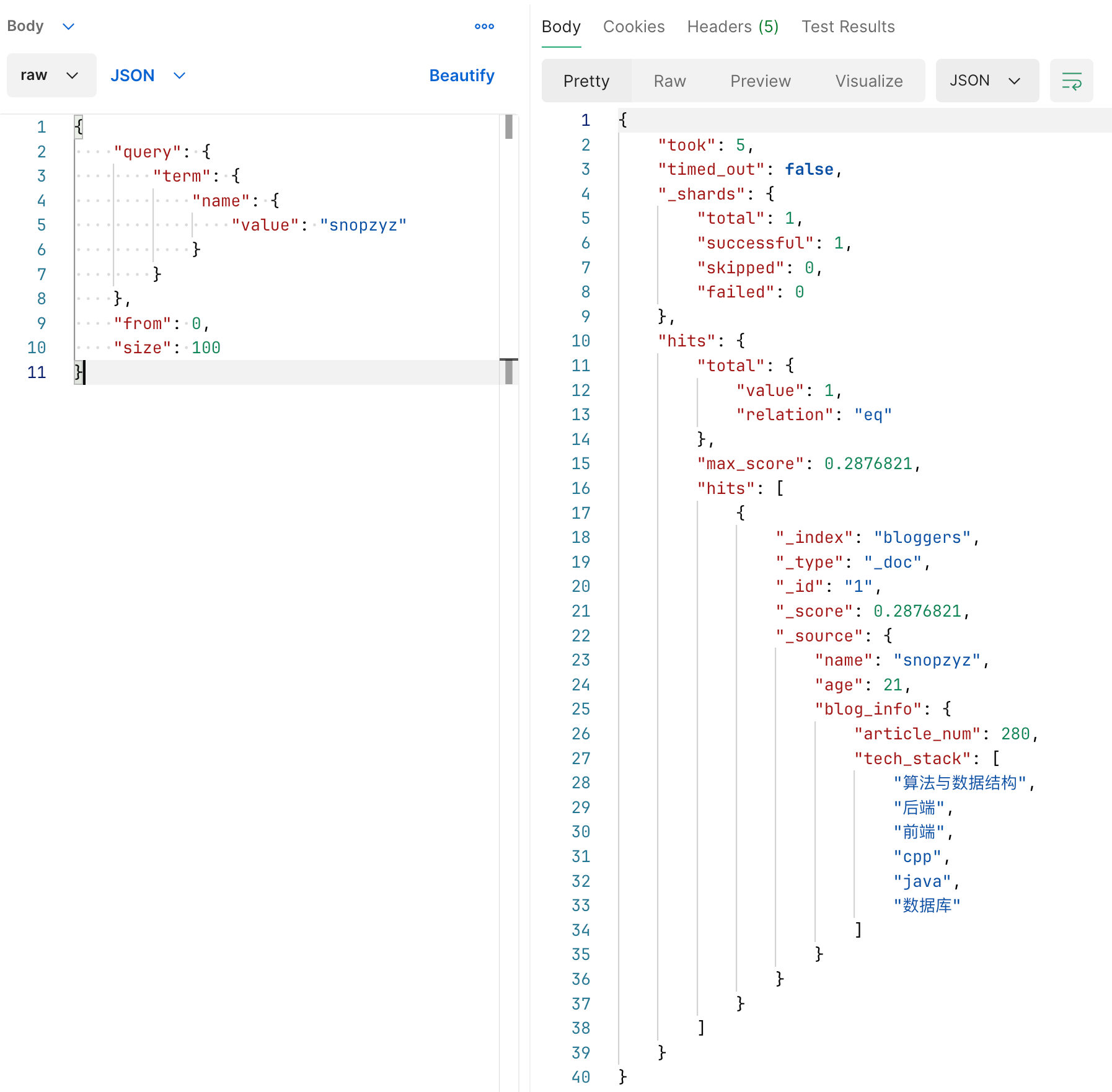
区别于分词全文检索我们这样查一下,就应当查不出来了。
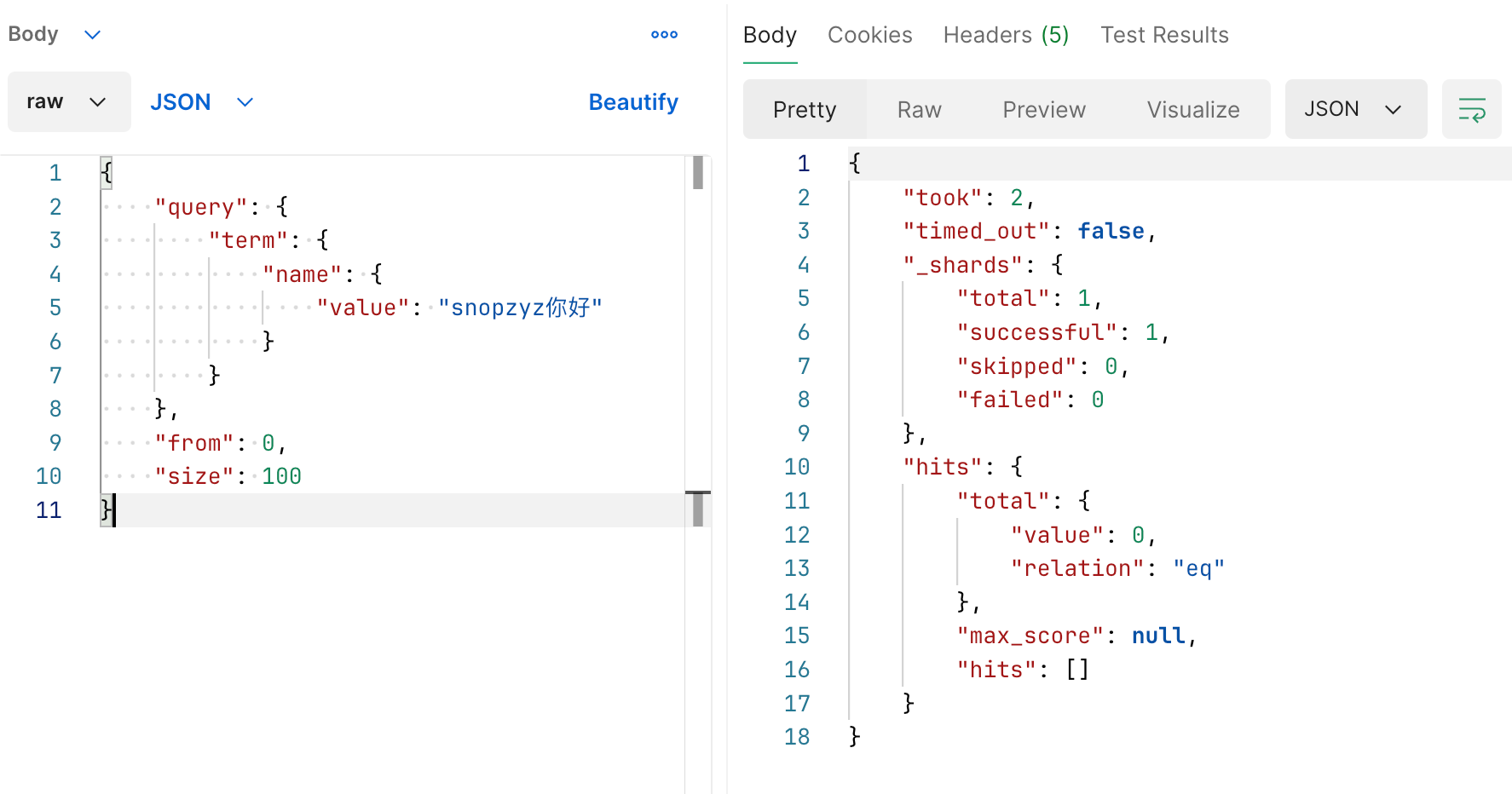
代码构建 QueryBuilder 如下:
// .termQuery("${字段名}", "${查询的值}")
QueryBuilders.termQuery("name", "snopzyz");
2
# terms
和上面的类似,但是支持一个字段查询多个值,只要有一个匹配就行,标准语法是。
"query" {
"terms": {
"${字段名}": [
"${查询值1}",
"${查询值2}",
...
]
}
}
2
3
4
5
6
7
8
9
示例
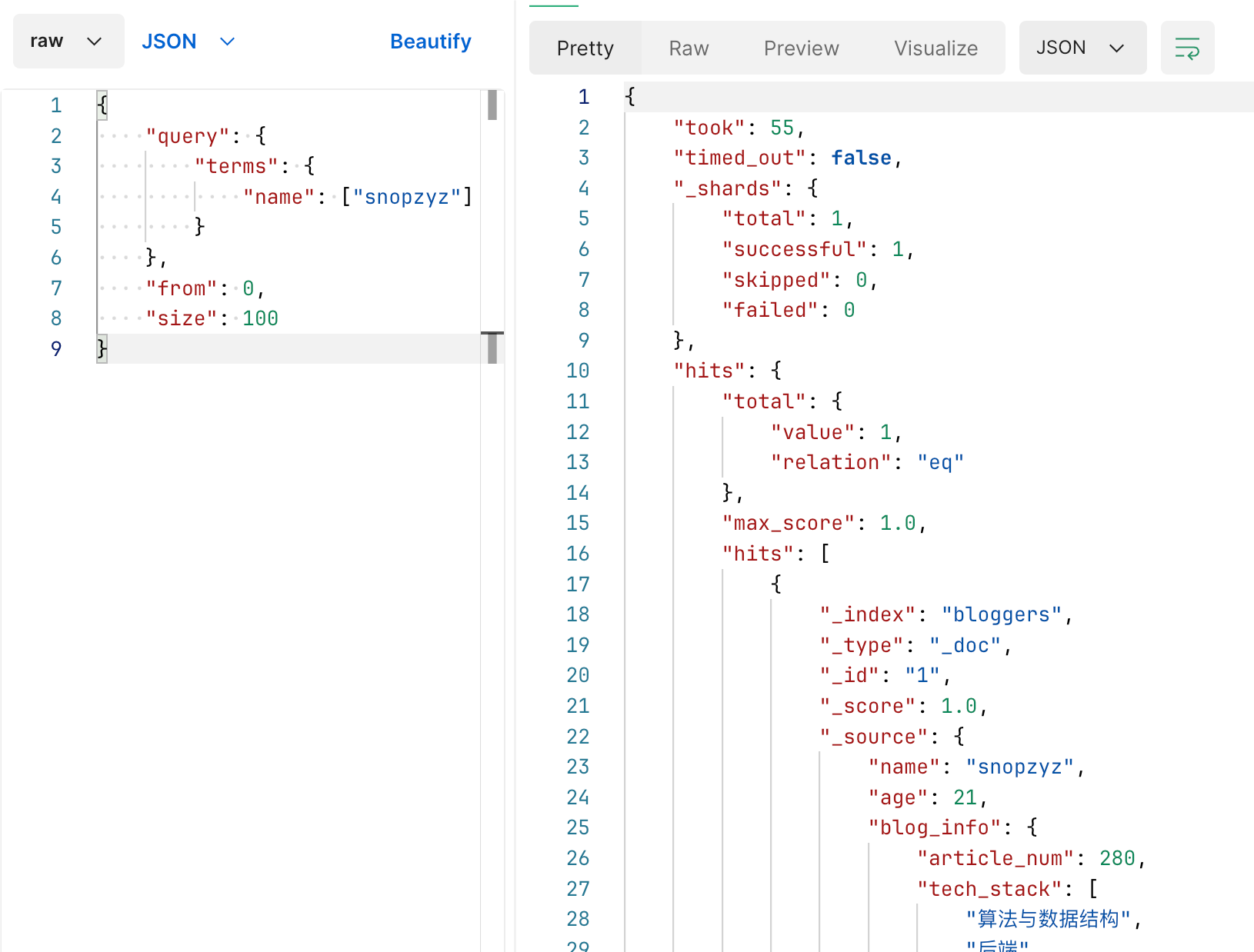
代码则可以追加 ${查询值} 也可以直接传入 List 来实现
// .termsQuery("${字段名}", "${查询值1}", "${查询值2}", ...
QueryBuilders.termsQuery("name", "snopzyz", "demo");
// .termsQuery("${字段名}", "${查询值组成的List}")
List<String> values = Arrays.asList("snopzyz", "demo");
QueryBuilder queryBuilder = QueryBuilders.termsQuery("name", values);
2
3
4
5
6
# range
区间查询,通常是对数值字段确定一个区间,匹配所有该字段满足在这个区间里面的文档。
标准查询模板为
"query": {
"range": {
"${字段名}": {
"${比较类型}": "${参照值}"
}
}
}
2
3
4
5
6
7
这个比较类型有四种:
gte:lte:gt:lt:
如我们查询 age 在 之间的文档
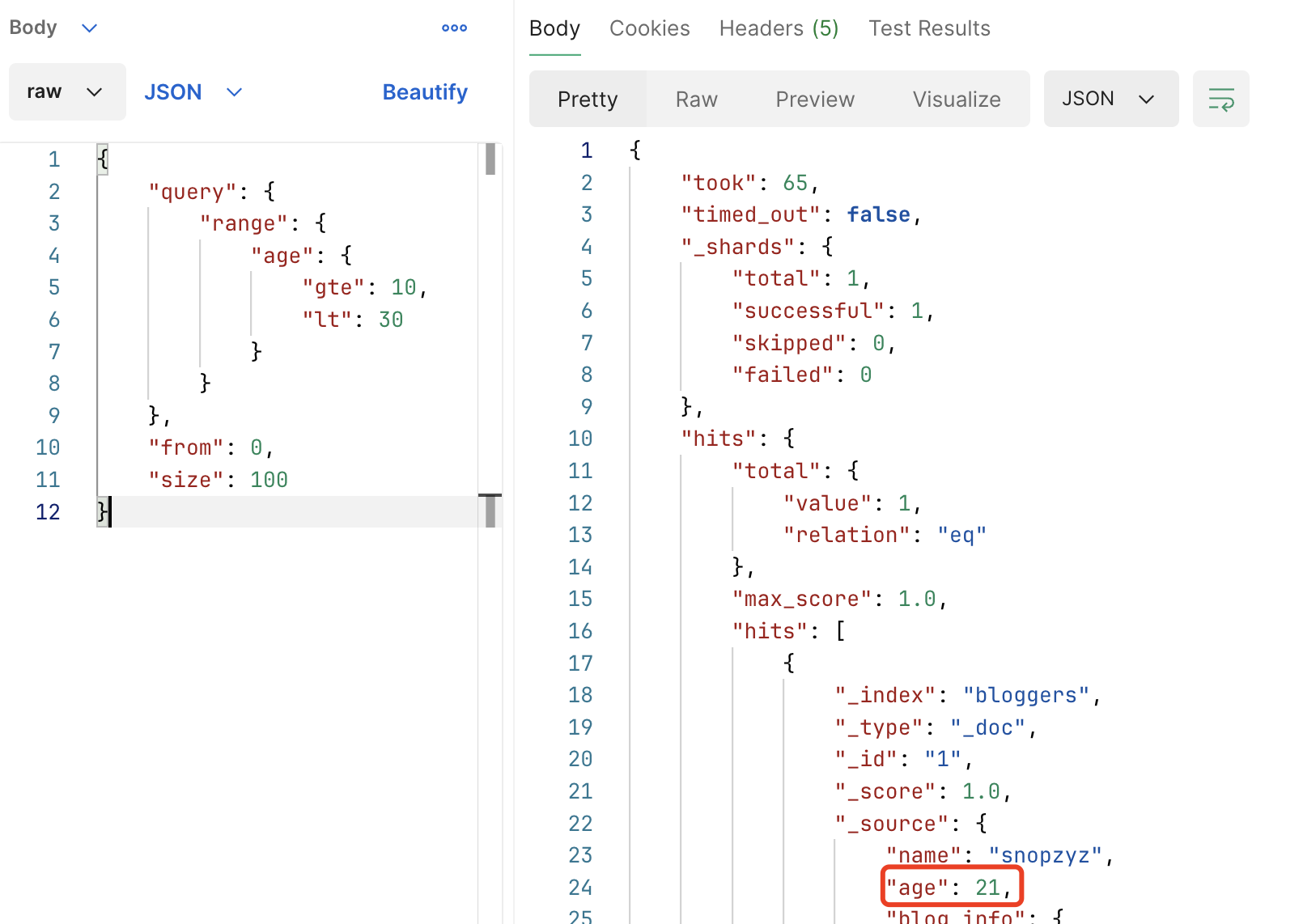
可以匹配到 age: 21 的这条记录,成功,代码构建 QueryBuilder 如下
// .rangeQuery("${字段名}").gte(${>=的数字}).lt(${<的数字})
QueryBuilders.rangeQuery("age").gte(20).lt(30);
2
# 复合查询
也称 bool 查询,可以结合多种查询子句来控制哪些文档包含在结果内,以及控制哪些文档的评分,有四种查询子句类型。
{
"query": {
"bool": {
"must": [],
"should": [],
"must_not": [],
"filter": []
}
}
}
2
3
4
5
6
7
8
9
10
这些查询子句内部就和 query 内一样,通常用来存放上面说的 “精确查询” 和 “全文检索”,其中
must:结果文档和查询内容必须匹配,且查询会影响评分should:查询可选- 若没有 must 查询:结果文档至少能对上 should 内的一条
- 若有 must 查询:条件和结果文档的显示性无关,只影响评分
must_not:和 must 对立,结果文档和查询内容必须不能匹配,但不影响评分filter:和 must 对应,不影响评分
如我要查询年龄是 21,博客技术栈不能包含 “高数” 的作者。
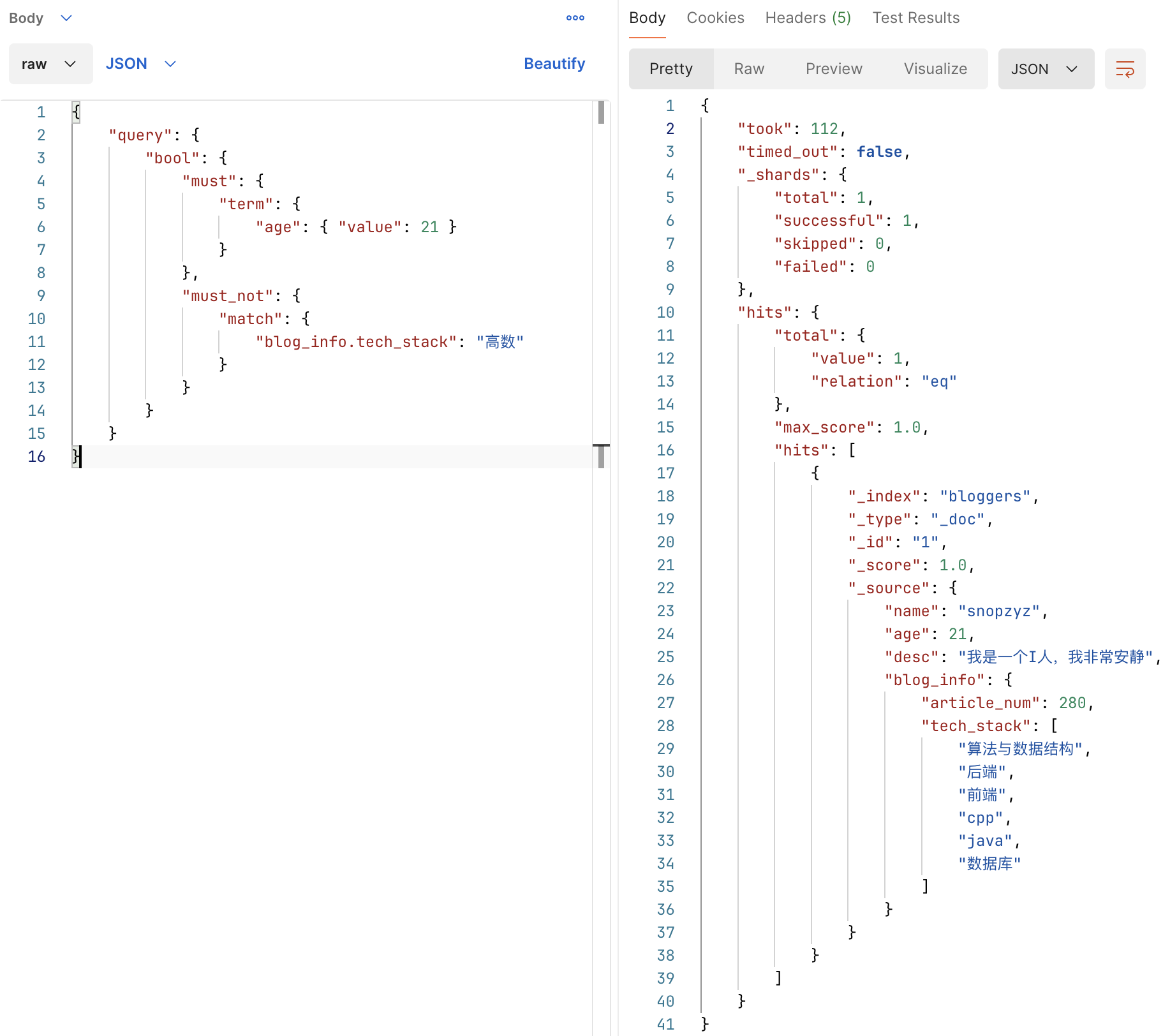
代码这里将之前使用的 QueryBuilder 替换为 BoolQueryBuilder。
类似于 DSL 的 { "must":{}, "filter":{} },通过直属于其下的方法 .must(...) 和 .filter(...) 来包裹具体的 QueryBuilder,来完成复合查询。
别的都是一样,甚至 request.source().query(...) 的参数也是支持 BoolQueryBuilder
实际演示如
SearchRequest request = new SearchRequest("bloggers");
// 写个 "bool"
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
// 内部写个 "must": { "term": { "name": "snopzyz" }}
boolQueryBuilder.must(QueryBuilders.termQuery("name", "snopzyz"));
// 内部写个 "filter": { "range": { "age": { "gt": 20 }}}
boolQueryBuilder.filter(QueryBuilders.rangeQuery("age").gt(20));
// 将整个 "bool":{...} 放入请求体内
request.source().query(boolQueryBuilder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
2
3
4
5
6
7
8
9
10
11
12
# 结果处理
# 排序
ES 默认按文档相关性得分排序,这里也可以自设定,格式为
{
"query": {},
"sort": [
{
"${排序字段}": "(String) ${排序规则: asc/desc}"
}
]
}
2
3
4
5
6
7
8
其中 sort 字段为 arrays ,内部按顺序存储的多个排序规则,是按顺序的多关键字排序。
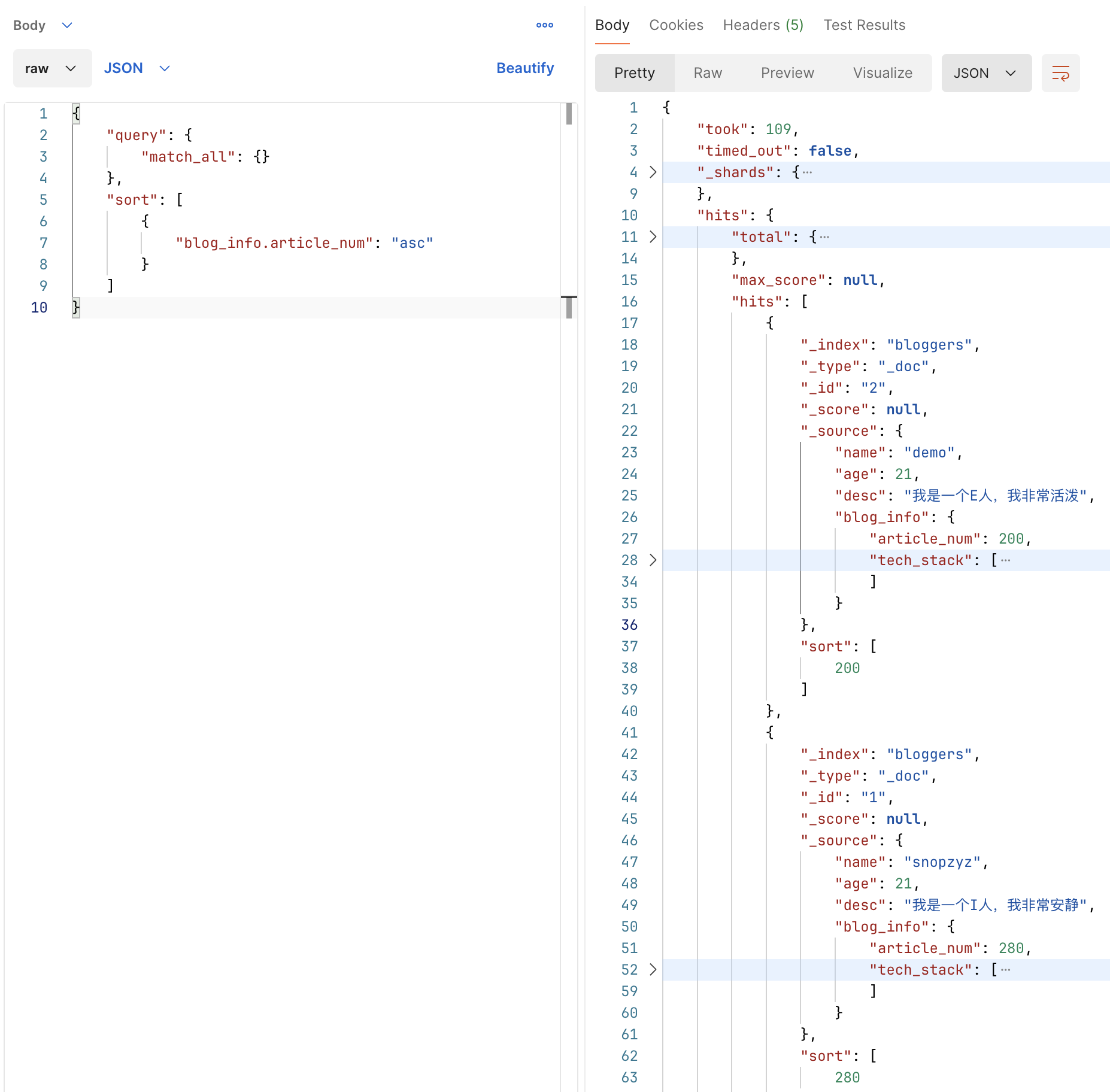
# 分页
分页就是我们前面一直使用的
{
"from": "(Number) ${起始位置}",
"size": "(Number) ${数据条数}"
}
2
3
4
使用方式非常简单不在这里讲了,但因 es 自带排序策略,分页需要注意深度分页发生的情况,具体部分可以了解 这里
上面两个一起说,排序分页对应的外部 json-key, from、size、sort,都和 query 是同级的。
所以替换掉的应该是 request.source() 后面的链式方法 .query,改为 request.source().from(${起始点}).size(${页面大小}).sort("${排序字段}", ${排序规则})
如
request.source().from(0).size(10).sort("age", SortOrder.ASC);
# 高亮
ES 为匹配信息提供了高亮的策略,其模板为
"highlight": {
"fields": {
"${匹配字段}": {
"pre_tags": ["(String) ${匹配到的高亮片段的前tag}"],
"post_tags": ["(String) ${匹配到的高亮片段的后tag}"],
"require_field_match": "(Boolean) ${当前字段和查询字段是否要是同一个字段}"
}
}
}
2
3
4
5
6
7
8
9
下面这样就新增了高亮的标签
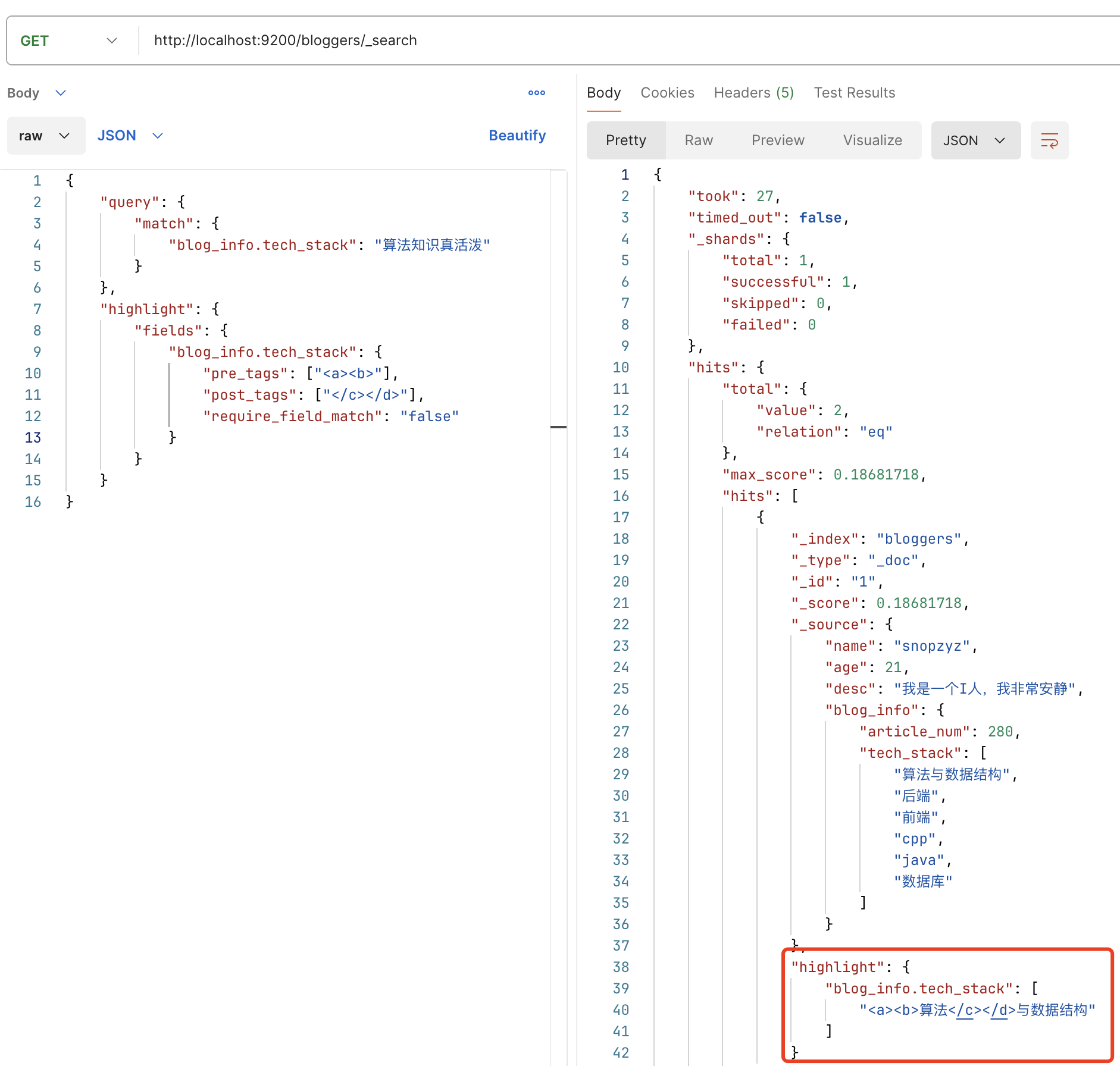
在 DSL 里面是 highlight,内部有字段名和对应规则,这里也是
request.source().highlighter(new HighlightBuilder()
.field("name")
.requireFieldMatch(false)
.preTags("<a>")
.postTags("</b>")
);
2
3
4
5
6
HighlightBuilder 可以构造的方法和对应 DSL 的字段都是一样的,但是注意一下在响应体内带标签的高亮内容不存在于 _source 字段内,而是 hightlight 字段内。
也就是

所以在代码解析结果时也应当调用 getHighlightFields(),即
...
// 解析响应结果
SearchHits searchHits = response.getHits();
searchHits.forEach(hit -> {
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
...
});
2
3
4
5
6
7
# 关于使用Restful-API发现的小TIPS
用了这么多,也能看到一些规律了,其实这个 API 和 RestFul 风格是对应的。
Request类的前缀大多数和 方法:url 有关,如GET方法获取文档和GetRequest,/_search的 url 和SearchRequest有关。request.source()值得是 json 请求体request.source().方法名指的是 json 请求体内的方法,如{ "query":{} }的内容用request.source().query(...)构造,{ "sort":{} }的内容用request.source().sort(...)构造
而响应的内容也有规律,Response 类的前缀总是和 Request 类相对应,response.XXX() 方法所指响应体内的字段,如我们最熟悉的几个 hits、tooks、...shares、scrollId 等,都在其中可以找到。
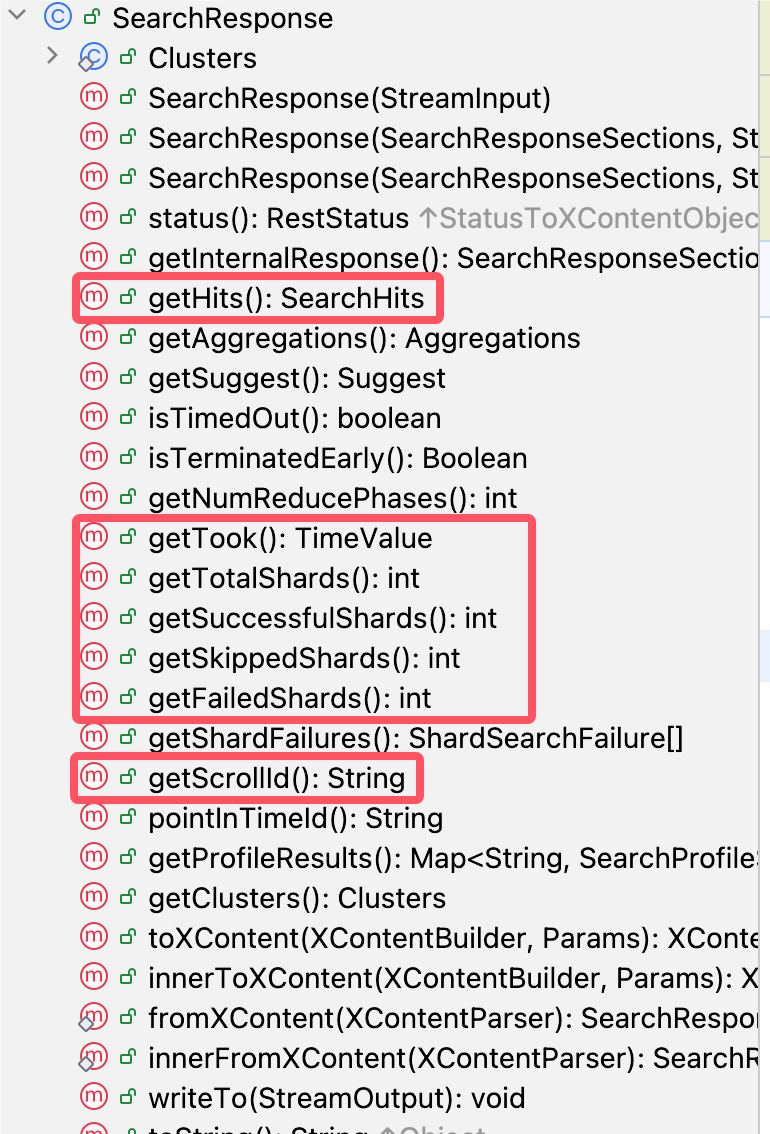
通过这些经验,我们可以很容易地模仿着 DSL 找到我们需要的内容。