IK分词器-中文断句
Chivas-Regal
es 作为一个检索工具,具有文档分词的能力,看一下用 post 请求 _analyze 做常规分词,请求体是文档和分词器名称
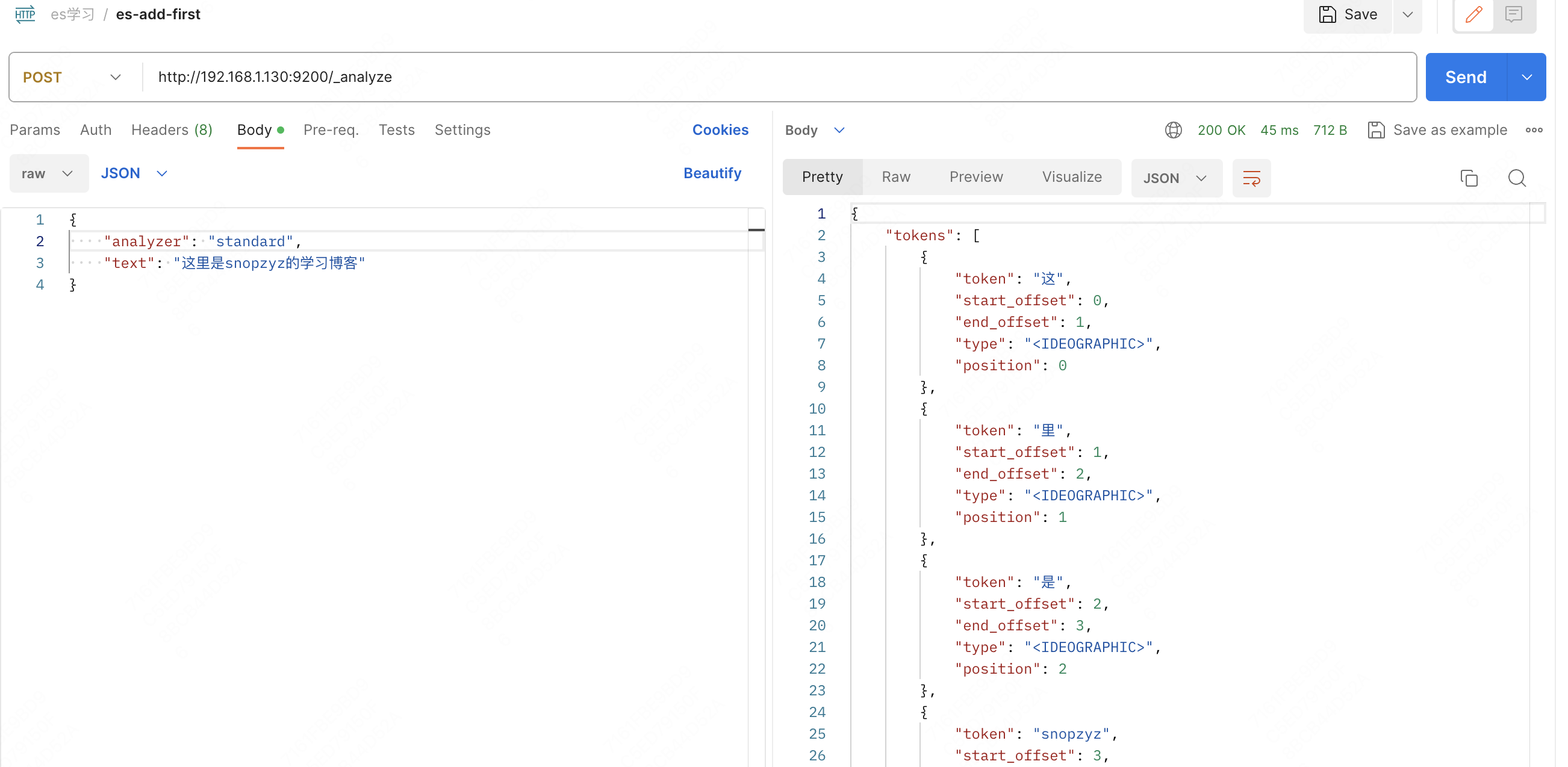
这说明了 es 分汉语时存在按字拆分的不足,此时需要借助一下插件 ik 分词器
从 这里 (opens new window) 找到与 es 对应的版本,下载压缩包,由于配置过数据卷,这里可以直接解压放进 es 容器宿主机的 /var/lib/docker/volumes/es-plugin/_data/ 下
然后重启容器 docker restart es
再用上面的文档,然后分词器的选择有两种:
- 最少切分:
ik_smart,只按含义将这文档拆一下 - 最细切分:
ik_max_word,将文档的每一个关键词全部提出来
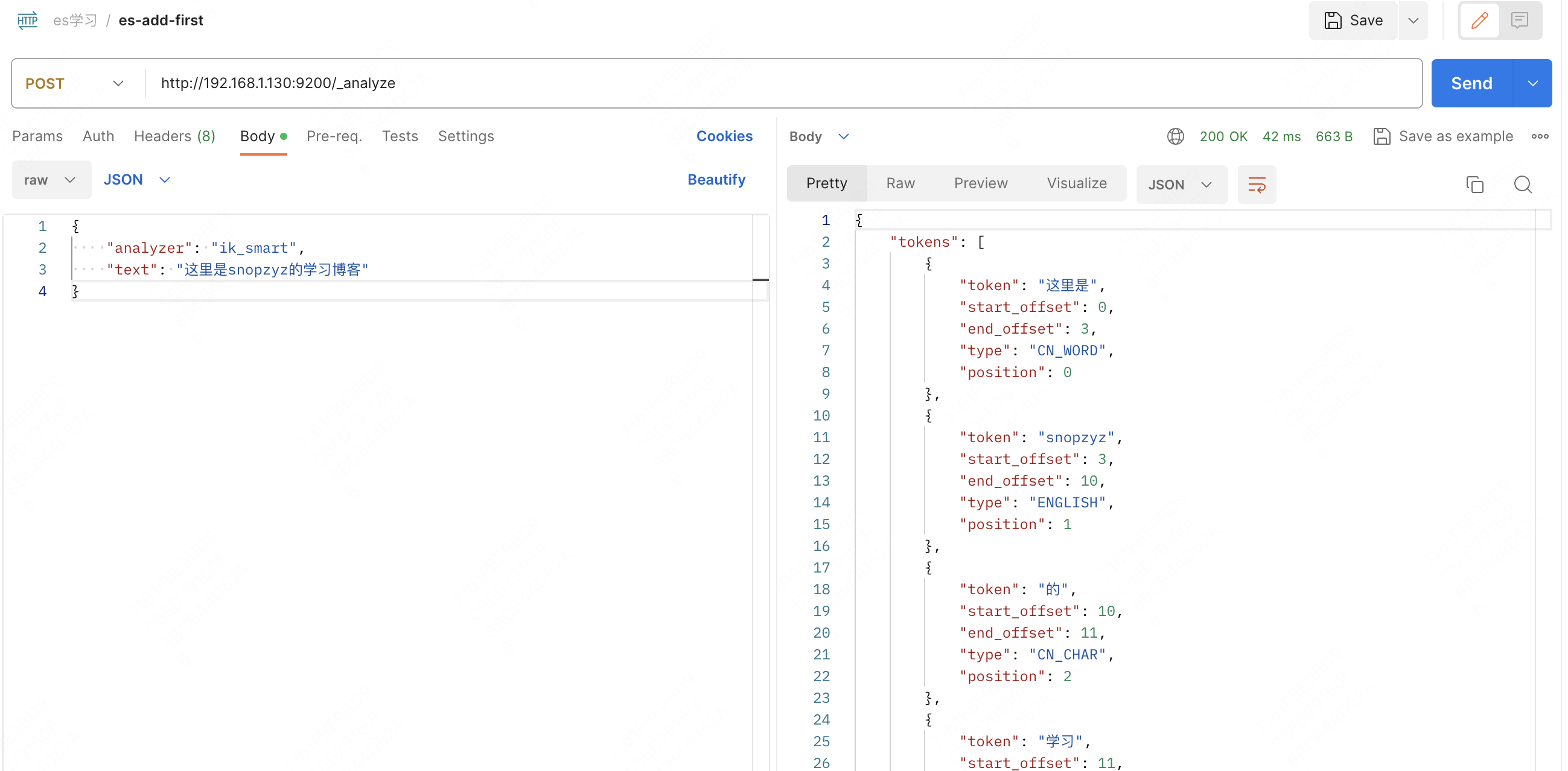
看一下实际情况
ik_smart:
ik_max_word:
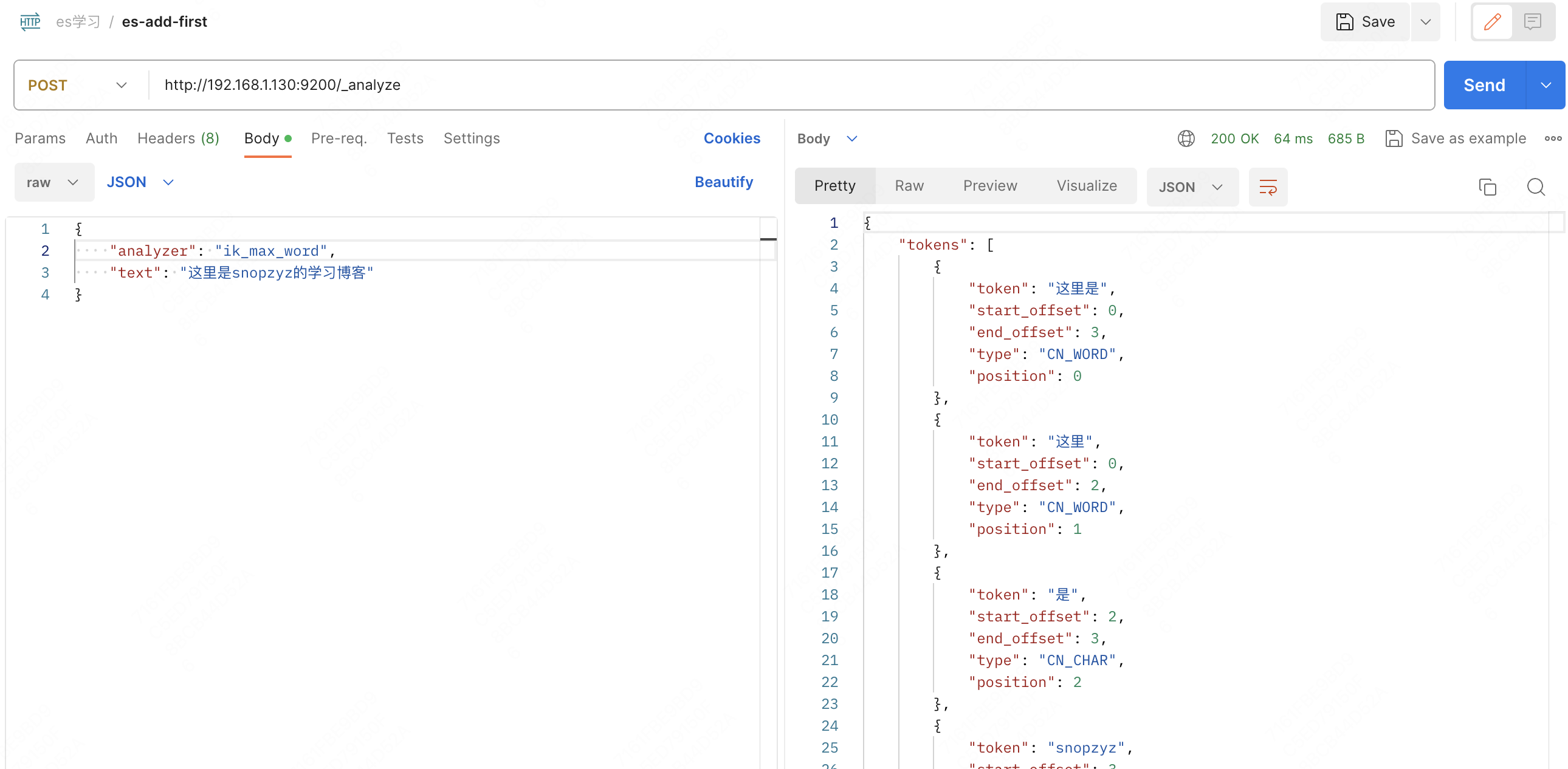
可以发现,ik_max_word 将所有可能的情况和词汇全部拆了出来,词汇多少和检索效率、精确度、保存时占用空间挂钩,要根据实际情况来选择最合适的分词器。
# 自定义词条
看一个情况:
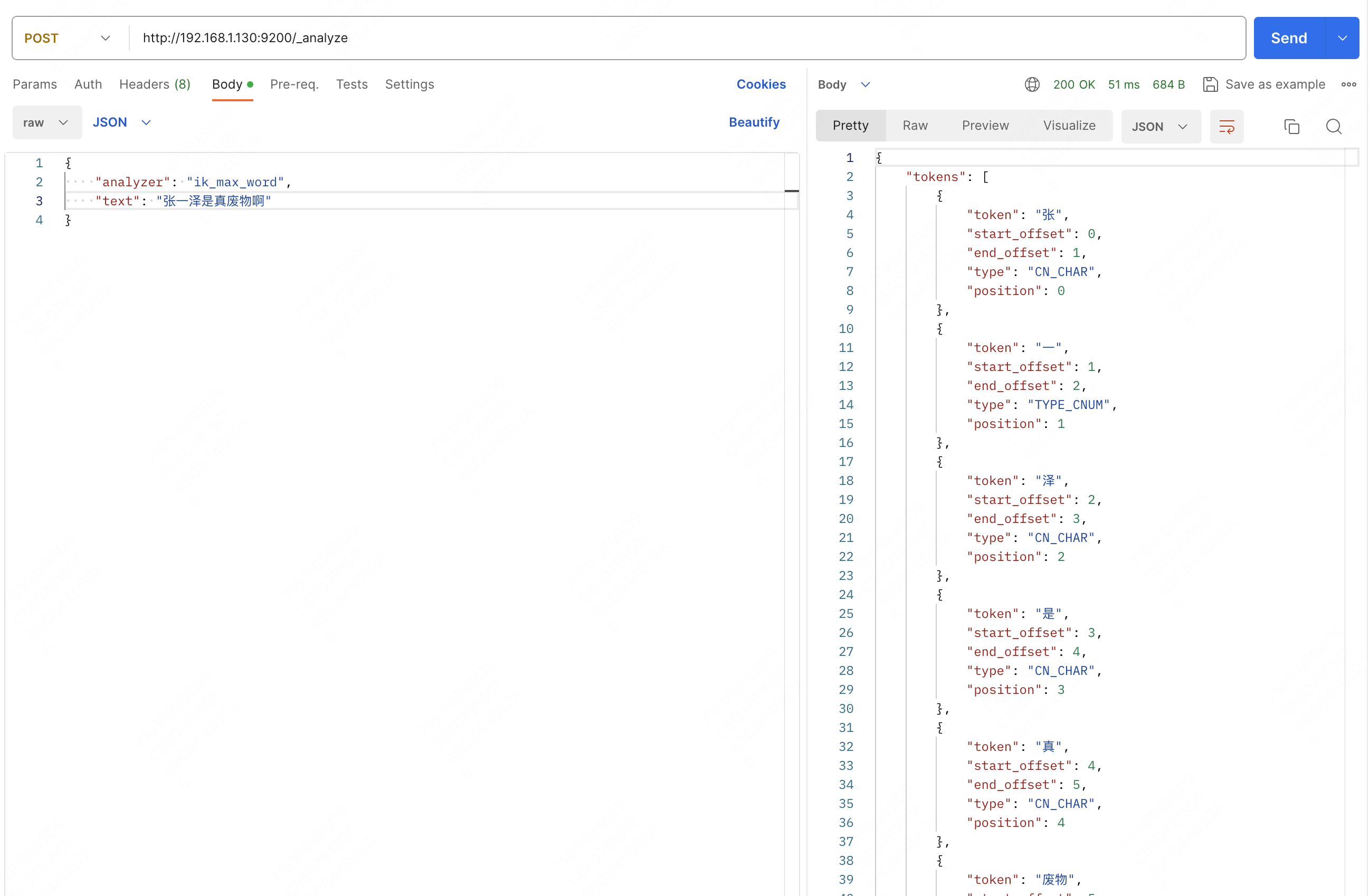
发现它好的不解析坏的倒是挺准的,这都是因为后台词典中数据的存在和不存在,对于这份词典,ik分词器支持词条扩展和停用。
首先进入 plugins 中 ik 分词器包下 config/IKAnalyzer.cfg.xml,根据注释在两个标签内添加扩展词典文件和停用词典文件。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stop.dic</entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
1
2
3
4
5
6
7
8
9
10
11
12
13
2
3
4
5
6
7
8
9
10
11
12
13
根据我们指定的文件名,去与这个配置文件同级的地方创建,然后重启 es 容器
echo 张一泽 >> ext.dic
echo 废物 >> stop.dic
docker restart es
1
2
3
2
3
再发送一遍刚刚的请求
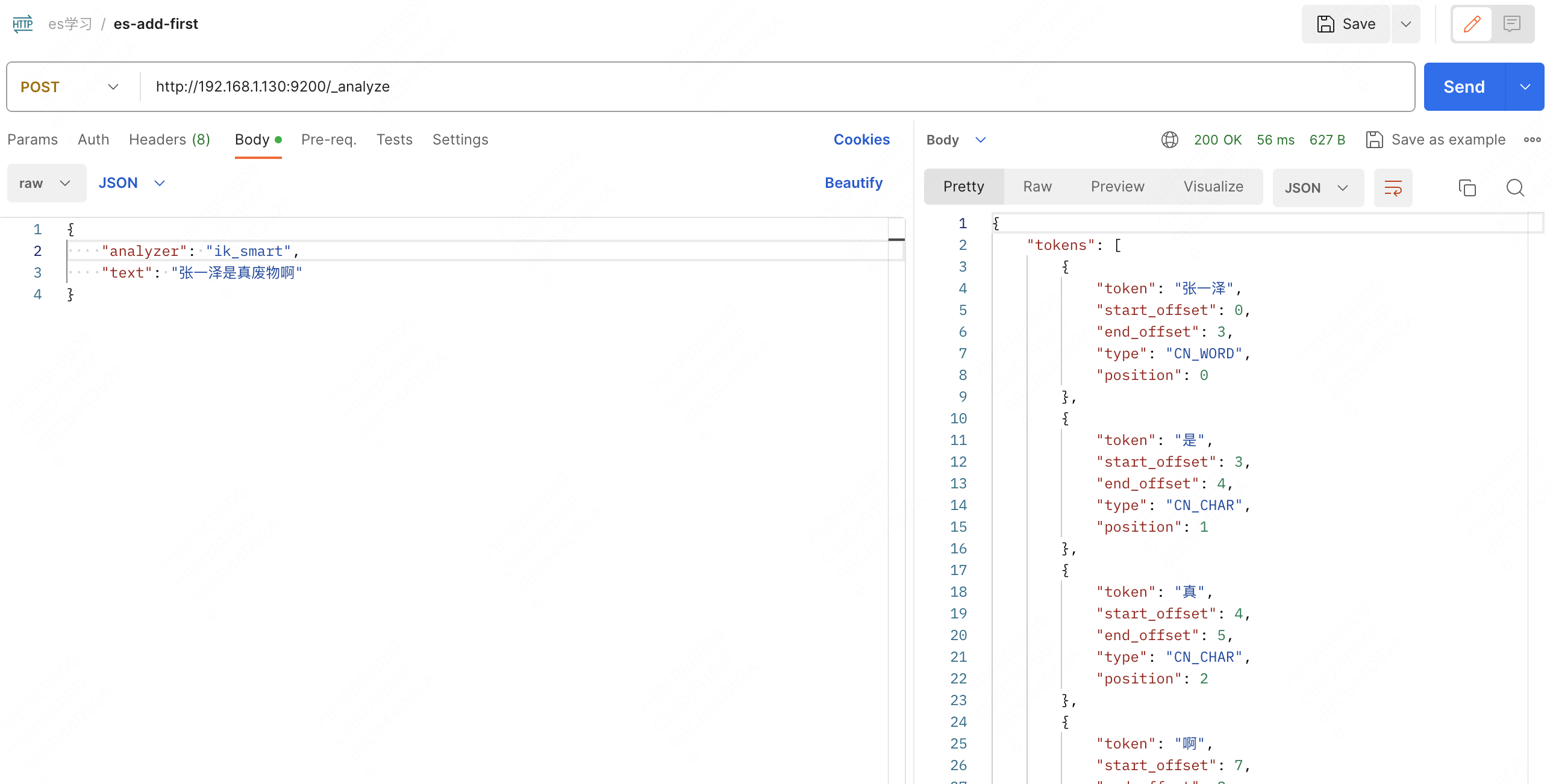
这次它就“文明”很多了,并且知道“张一泽”是一个词语了。
这种自定义词条可以排除掉敏感词汇,并且添加一些新兴词汇的解析。