入门、配置与启动
# Kafka 基本概念
Kafka是一个分布式、支持分区多副本的消息系统,常用语日志收集、消息收发、用户活动跟踪、运营指标等场景。
在早期 Kafka 依赖于 zookeeper 存储有关分区和代理的元数据,而在 2021/04/19 的 2.8.0 版本中用自管理的 Quorum 代替了 ZooKeeper 的功能。
# 角色与术语
在 Kafka 中有这样一些信息
- broker:消息处理节点,代表一个 Kafka 节点
- topic:Kafka 收到消息后会根据 topic 进行归类,来发送给订阅对应 topic 的消费者
- producer:消息生产者,代表向 broker 发送消息的客户端
- consumer:消息消费者,代表从 broker 读取消息的客户端
- consumer-group:消息消费者组,由多个 consumer 组成,一个分区下的消息可以发送给多个 consumer-group ,但一个 consumer-group 只有一个 consumer 可以消费信息
- partition:分区,一个 topic 可以分为多个 partition,每个 partition 的内部消息是有序的
# 第一个 Kafka 服务
首先需要保证你的机器中有 jdk 并且存在一台运行 zookeeper 的机器
首先在 官网 (opens new window) 下载 Kafka,这里版本使用 2.4.1 ,将其解压到我们的机器中(这里选择路径为 /usr/local/kafka )
# 配置文件
进入 config 目录下的 server.properties ,修改其中的几个地方
- 设置集群中唯一的
broker.id=0 - 添加 Kafka 向外开放的地址,
listeners=PLAINTEXT://<你的机器的ip地址>:9092 - 设置日志文件保存位置,修改为
log.dirs=/usr/local/kafka/data/kafka-logs - 设置保存数据的 zookeeper 地址,
zookeeper.connect=<你的zookeeper机器的ip地址>:2181
这里写好的这四个信息是这样的,其他的属性都不用改
broker.id=0
listeners=PLAINTEXT://192.168.1.120:9092
log.dir=/usr/local/kafka/data/kafka-logs
zookeeper.connect=192.168.1.111:2181
2
3
4
# 启动 Kafka
命令格式为 <你的kafka安装包地址>/bin/kafka-server -start.sh <server.properties配置文件地址>
这里再开一个守护进程运行模式
cd /usr/local/kafka/kafka_2.11-2.4.1/bin
./kafka-serve-start.sh -daemon ../config/server.properties
2
此时进入 zookeeper 的机器中通过 zkCli.sh 进入客户端后查看 / 下的节点会发现

产生了非常多的节点
此时查看 /brokers/ids 后会看到里面多出来了一个 0,就是我们运行的 Kafka 在 config/server.properties 中的 broker.id
# 创建 topic
通过如下命令
./kafka-topics.sh --create --zookeeper 192.168.1.111:2181 --replication-factor 1 --partitions 1 --topic test
其中 192.168.1.111 是我在局域网中的 zookeeper 主机地址,这段命令表示 “在192.168.1.111:2181(zookeeper进程地址)创建(create)名为test(topic)的topic,有1(replication-factor)个备份,有1(partitions)个分区”。
并且可以看一下是否创建成功(有哪些 topic)
./kafka-topics.sh --list --zookeeper 192.168.1.111:2181

# 生产消息
根据上面说的生产者 producer,Kafka 内置生产者客户端 kafka-console-producer.sh 可以调用
生产消息要指定 broker 的地址与 topic 信息
./kafka-console-producer.sh --broker-list 192.168.1.120:9092 --topic test
因为我的 kafka 进程地址为 192.168.1.120:9092,于是在 broker-list 中写的是这个地址,并且指定 topic 为 test。
执行后会产生一个带有前缀 > 的客户终端,在里面写的一行行消息就是要传递给 broker 的字符串。

# 消费消息
根据上面说的消费者 consumer,Kafka 内置有 consumer 客户端 kafka-console.consumer.sh 供我们调用
消费消息的时候要指定从哪台 kafka 服务器,哪个 topic 接收消息
./kafka-console-consumer.sh --bootstrap-server 192.168.1.120:9092 --topic test
这种是不接收历史消息,而是从当前消息开始,比如下面这样的流程
- 生产者发送
hello - 消费者开启
- 生产者发送
kafka,消费者接收到kafka
生产者:

消费者:

可以看到消费者只消费了一个信息,如果要消费到历史的数据,要加上一个 --from-beginning
也就是
./kafka-console-consumer.sh --bootstrap-server 192.168.1.120:9092 --from-beginning --topic test

这里就传入了所有的历史数据
是否显示历史数据的原理:
Kafka 的消费组维护了个已经读取消息数量的偏移量信息
- 当一个消费者连接不展开历史数据时,Kafka 会令该消费者从偏移量为当前消息数+1的位置开始读,也就是不读之前的历史数据
- 当一个消费者连接读取历史数据时,根据消费组记录的已读取的偏移量信息,Kafka 会令偏移量为上次结束时读取到的位置+1,也就是读取上次断开之后生产者在该 topic 下生产的所有消息
这样通过偏移量就实现控制了消费者的消息读取起点。
它们存放在存放 log 目录下的“主题-分区”的文件夹内。

在此之前先介绍一下文件夹的格式,进入我们创建的 test-0

这里有三个文件介绍一下
- 000...000.log:存放 topic 下的消息
- 000...000.index:以偏移量做的稀疏索引
- 000...000.timeindex:以创建时间做的稀疏索引
而之前展示的 __consumer_offsets-x 文件夹,则是 kafka 创建的 __consumser_offsets 主题下的 50 个分区,用来存放消费者消费某个主题的偏移量。
当一个消费者挂掉的时候,它会把偏移信息 “consumerGroupId+topic+分区号:当前offset值” 放置在 __consumer_offsets 主题中,而该主题创建 50 个分区就可以支持多个消费者的分布式化(计算 hash 值判断应该提交进哪个分区内)并行提交信息。
(分区就是对 topic 的消息做的划分,具体概念先不在这里说明)
# 消息的单播与多播
在 角色与术语 中提到过,一个消费组收到一条消息,只会由其中的一个消费者消费。
按上面的生产消费指令在一个 kafka 会话中启动一台连接了 topic=test 的生产者。
然后再开两个会话对该 topic 启动两个消费者,由生产者发送一个消息后会发现消息只会被后启动的消费者消费,这便是单播。
而将后启动的那个会话停掉之后,发送的消息就又会被剩余的那个消费者接收。
如果想同时由多个消费者消费这条消息,就需要建立多个消费组。
在两个消费者会话中的启动命令分别带上 --consumer-property group.id=<一个消费组的名称> ,比如
./kafka-console-consumer.sh --bootstrap-server 192.168.1.120:9092 --consumer-property group.id=testGroup1 --topic test
./kafka-console-consumer.sh --bootstrap-server 192.168.1.120:9092 --consumer-property group.id=testGroup2 --topic test
2
此时生产者发送消息后,分别位于两个消费组的两个消费者均可接收消息,这便是多播。
# 查看消费组信息
查看只需要这个命令
./kafka-consumer-groups.sh --bootstrap-server 192.168.1.120:9092 --describe --group <消费组的名称>
然后会给出一些字段和组内每个消费者的信息,这些字段需要重点关注的是:
CURRENT-OFFSET:当前消费组已消费的偏移量LOG-END-OFFSET:主题对应分区消息的结束便宜量LAG:当前消费组未消费的消息数(积压数)
比如这里调用指令
./kafka-consumer-groups.sh --bootstrap-server 192.168.1.120:9092 --describe --group testGroup1

这里当前结尾偏移量信息还是 ,如果关掉消费者然后再在生产者生产一条消息

这里就变成了
# 主题与分区
主题是一个逻辑概念,它是划分消息的标识。
分区则是将一个 topic 中的消息分布式存储,解决了 “统一存储文件过大导致的各种维护、读写性能的问题,与读写串行下的吞吐量过低” 的问题。
假设有一个 broker ,它有两个分区 1 和 2。
还有一个消费组,它有两个消费者 A 和 B。
分区1连接了消费者A,分区2连接了消费者B(假设主题都是一样的)。
那么由于一个 broker 收到消息后会被均匀分发到两个分区,所以向这个 broker 发送消息会同时被两个消费者均匀地接收。
同时需要注意的是消息只能在一个 partition 内保证消息的局部顺序性,但是多个 partition 发送消息的顺序却不能由 kafka 内部保证。
我们可以用下面的命令来创建一个多分区的主题:
./kafka-topics.sh --create --zookeeper 192.168.1.111:2181 --replication-factor 1 --partitions 2 --topic testWithMorePartitions
然后进入我们指定存放 log 文件的目录

发现这里建立了两个 testWithMorePartitions 的目录,也就是意味着两个分区
# 集群
先创建三个 properties 作为三台 broker 的启动配置文件,与之前配置的相比具体要改的是这些内容
broker.id=<在集群中的broker唯一编号>
listeners=PLAINTEXT://<提供服务的ip:port>
log.dirs=<日志文件存放位置>
2
3
例如这里不开三台机器了,用端口号来区分
# server-9092.properties
broker.id=0
listeners=PLAINTEXT://192.168.1.120:9092
log.dirs=/usr/local/kafka/data/kafka-logs-9092
2
3
4
5
与
# server-9093.properties
broker.id=1
listeners=PLAINTEXT://192.168.1.120:9093
log.dirs=/usr/local/kafka/data/kafka-logs-9093
2
3
4
5
与
# server-9094.properties
broker.id=2
listeners=PLAINTEXT://192.168.1.120:9094
log.dirs=/usr/local/kafka/data/kafka-logs-9094
2
3
4
5
然后分别以这三个文件启动三台 broker
./kafka-server-start.sh -daemon ../config/server-9092.properties
./kafka-server-start.sh -daemon ../config/server-9093.properties
./kafka-server-start.sh -daemon ../config/server-9094.properties
2
3
接着进入依赖的 zookeeper 机器启动客户端查看 /brokers/ids 下的节点

这样就说明启动了三台 broker 了
# 副本
之前在启动的时候总是带有一个 --replication-factor 1 用来指代有几个副本,副本是对分区的备份,在集群中不同的副本会被部署到不同的 broker 上。
现在已经有了多台 broker ,这里在一台 broker 上制作一个多副本的 topic:
./kafka-topics.sh --create --zookeeper 192.168.1.111:2181 --replication-factor 3 --partitions 2 --topic topicWithMoreReplicationFactor
然后再查看一下这个 topic 的信息:
./kafka-topics.sh --describe --zookeeper 192.167.1.111:2181 --topic topicWithMoreReplicationFactor

这里每一个分区都存在自己的 Leader ,这里的 Leader 就是负责对该分区产生的副本进行读写的角色,对应另一种角色为 Follower,此时别的 Followers 就仅能对该副本进行读。
此时生产者会将要发送到某个分区的消息,发送到该分区的 Leader 下的副本中,其他 Followers 就仅能对 Leader 的副本进行同步。
而 isr 存放可以同步和已同步的 broker 节点(可能存在节点会因为同步速度过低而禁止同步该副本),而当 Leader 挂掉后由于 isr 集合中副本都是完善的,就会从该集合中选举出新的 Leader。
再关注一下 data 内的日志结构
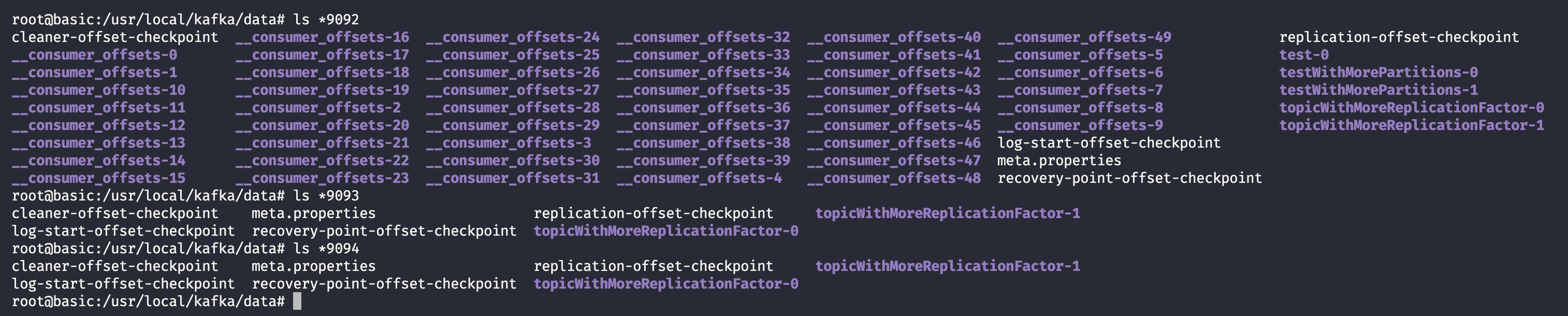
首先 __consumer_offsets-x 只会在一个 broker 上有,保存消费者读取位置的信息太大了,整个集群有一份即可,而我们在集群中创建的 topic 则会保存在三台 broker 上。
# 收发消息
基本的命令就是相比于之前来说将 broker-list 和 bootstap-server 的节点写为三个 ip:port
生产者调用命令
./kafka-console-producer.sh --broker-list 192.168.1.120:9092,192.168.1.120:9093,192.168.1.120:9094 --topic topicWithMoreReplicationFactor
消费者调用命令
./kafka-console-consumer.sh --bootstrap-server 192.168.1.120:9092,192.168.1.120:9093,192.168.1.120:9094 --topic topicWithMoreReplicationFactor
# JavaAPI
# 生产者
# 基本使用
首先惯例导入 Kafka 坐标
<!-- pom.xml -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.4.1</version>
</dependency>
2
3
4
5
6
7
然后分析一下我们生产者启动的指令:
./kafka-console-producer.sh --broker-list 192.168.1.120:9092,192.168.1.120:9093,192.168.1.120:9094 --topic topicWithMoreReplicationFactor
这里主要是一些配置属性,指定 broker 节点,以及我们要发送的 topic ,由于在发送时指定 topic 会更方便,所以这里只看 broker 节点。
Java 中 Kafka 的生产者叫做 KafkaProducer ,是 Producer 的实现类,于是初始化一个,同时指定 Properties 参数,参数的 Key 都放在 ProducerConfig 中了。
一个最简单的生产者要配置的就是 broker 和一些序列化器。
Properties props = new Properties();
// broker-list
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.1.120:9092,192.168.1.120:9093,192.168.1.120:9094");
// key 的序列化器(key是什么等下面会说)
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// value 的序列化器
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// kafka 生产者
Producer<String, String> producer = new KafkaProducer<>(props);
2
3
4
5
6
7
8
9
这里 value 都知道是消息本体,key 是什么下面会说。
配置完了需要消息体 ProducerRecord ,初始化时指定一下 topic-name 和消息即可。
ProducerRecord<String, String> producerRecord = new ProducerRecord<>(TOPIC_NAME, "hello kafka");
发送方式就是通过 Producer#send 来发送,这个方法的返回值调用 get() 可以获取到发送完数据之后该 topic 的状态的元数据。
RecordMetadata metadata = producer.send(producerRecord).get();
System.out.println("topic = " + metadata.topic());
System.out.println("partition = " + metadata.partition());
System.out.println("offset = " + metadata.offset());
2
3
4
总的来说就是这样:
// 配置 broker-list 和 序列化器
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.1.120:9092,192.168.1.120:9093,192.168.1.120:9094");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 构造生产者
Producer<String, String> producer = new KafkaProducer<>(props);
// 构造生产的消息记录
ProducerRecord<String, String> producerRecord = new ProducerRecord<>(TOPIC_NAME, "hello kafka");
// 发送并获取到 topic 状态
RecordMetadata metadata = producer.send(producerRecord).get();
System.out.println("topic = " + metadata.topic());
System.out.println("partition = " + metadata.partition());
System.out.println("offset = " + metadata.offset());
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
我们运行一下这一段代码,然后在命令行那边的消费者即可看到消息
# 消息记录构造方法
ProducerRecord 构造的时候我们会看到有很多可以用的参数,这里来说明一下
String topic:指代要发送到的 topic 名称Integer partition:指代要发送到的 topic 下的分区K key:K 是泛化的类型参数中之一,在设置的序列化器中转化为 byte ,用处在于可以通过hash(key)%partitionNum来确定被发送到哪个分区中,若同时设置了partition和key,则会发送到 partition 对应的分区中V value:V 是泛化的类型参数其中之一,在设置的序列化器中转化为 byte,表示消息的实体Long timestamp:消息的时间戳,发送时可以带上System.currentTimeMillis()来发送表示消息创建的时间Iterable<Header> headers:一个集合,内部含有多条 Header 表示消息头
# 发送消息的同步异步
Producer 在处理消息发送时有两种方式,一种是上面我们演示的调用 send 然后通过 get 获取元数据的方式,也是一种消息的同步发送机制,它在安全状态下应当以如下形式发送:
try {
RecordMetadata metadata = producer.send(producerRecord).get();
System.out.println("topic = " + metadata.topic());
System.out.println("partition = " + metadata.partition());
System.out.println("offset = " + metadata.offset());
} catch (InterruptedException e) {
e.printStackTrace();
// 业务操作:重试 or 记录
}
2
3
4
5
6
7
8
9
这种方式就保证了消息发送未成功时应该怎么做,可以嵌套多个发送来完成消息的重发或日志记录。
另外有一种异步发送的机制,即设置一个回调函数处理消息发送后的操作。
producer.send(producerRecord, new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e == null) {
log.error("消息 " + producerRecord + " 发送失败:" + e.getStackTrace());
} else if (recordMetadata != null) {
System.out.println("topic = " + recordMetadata.topic());
System.out.println("partition = " + recordMetadata.partition());
System.out.println("offset = " + recordMetadata.offset());
}
}
});
2
3
4
5
6
7
8
9
10
11
12
异步发送对性能确实有提升作用,提高了 broker 的吞吐量,但值得一提的是这种机制产生消息丢失的概率会更大,因此这种机制更多应用在对速度要求高同时对消息是否发送成功要求不大的场合。
因业务需要作者暂时进行 es 板块的更新,Kafka 应用学习暂时告一段落,恢复时间待定。