检索下的相关性得分
相关性得分是 ES 进行 DSL 检索文档时,对匹配程度计算的得分,在展示时默认是倒序排序,也就是说越靠前的匹配度越高。
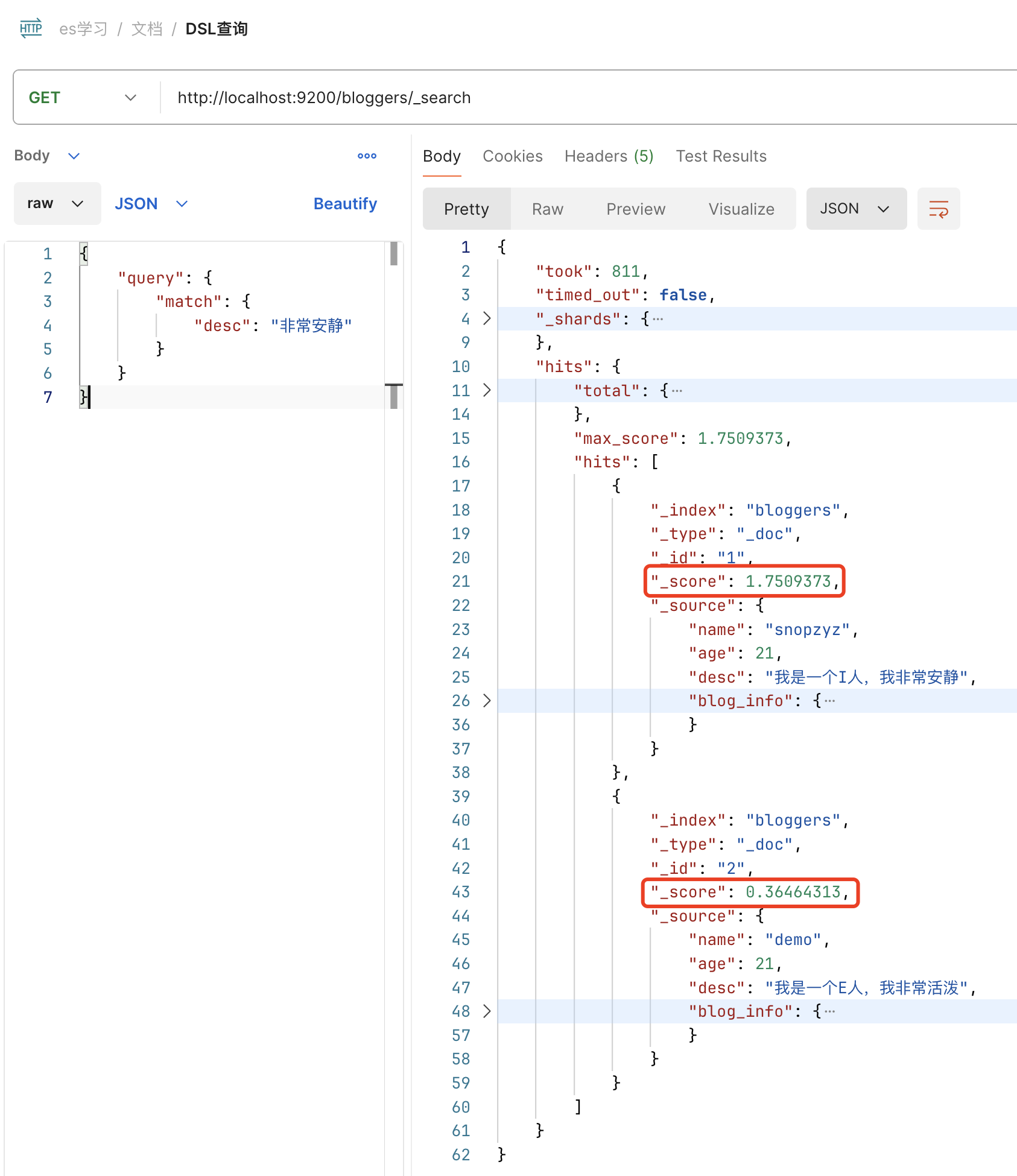
如上可以看出,全文检索分词后 “非常”,“安静” 在 snopzyz 能匹配两条,在 demo 只能匹配一条,故圈起来的部分显示 snopzyz 匹配度更高,排在前面。
# 得分计算
而 ES 在相关性得分计算上考虑得比较多,讲解一下使用到的两个算法。
先了解两个术语:
逆文档频率 :用来分析一个词语在文档中出现的频率。
公式
- 是文档总数
- 是包含词 的文档数目
词频 :用来度量一个词语的普遍重要性。
公式
- 是词 在文档 中的出现次数
故可知分母是文档 中所有词的出现次数之和。
# TF-IDF 算法
使用于 ES v5.0 之前,全名 Term Frequency-Inverse Document Frequency。
其直接使用 “逆文档频率” 和 “词频” 的乘积来评估词条对文档的重要程度,特点是随词频增加变得越来越大。
公式就跟描述的一样:
# BM25 算法
使用于 ES v5.0 之后,是 Okapi BM25 的简称。
其考虑了其他因素如文本长度,来进行更为实际的计算,特点是增长曲线随着词频增加会趋于水平。
公式:
- :查询中的第 个词。
- :词 的逆文档频率。
- :词 在文档 中的频率。
- :文档 的长度(即词的数量)。
- :所有文档的平均长度。
- 和 :可调参数,通常 和 。
# 计算修改
可以在查询时设定一些简单的规则来定义某些文档的得分。
DSL 模板如下
"query": {
// 带自定义计算得分查询
"function_score": {
"query": {
// 查询规则
},
// 得分计算
"functions": [
{
"filter": "(Object) 过滤条件,与 query 内的语法一致,且只要查询到了就给通过",
"${算分返回规则}": "(Any) ${对应计算方式}"
}
],
"boost_mode": "(String) ${与query_score的加权模式}",
"score_mode": "(Strig) ${多个function_score的加权模式}"
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
给出一个例子,方便下面可以代入熟悉字段含义
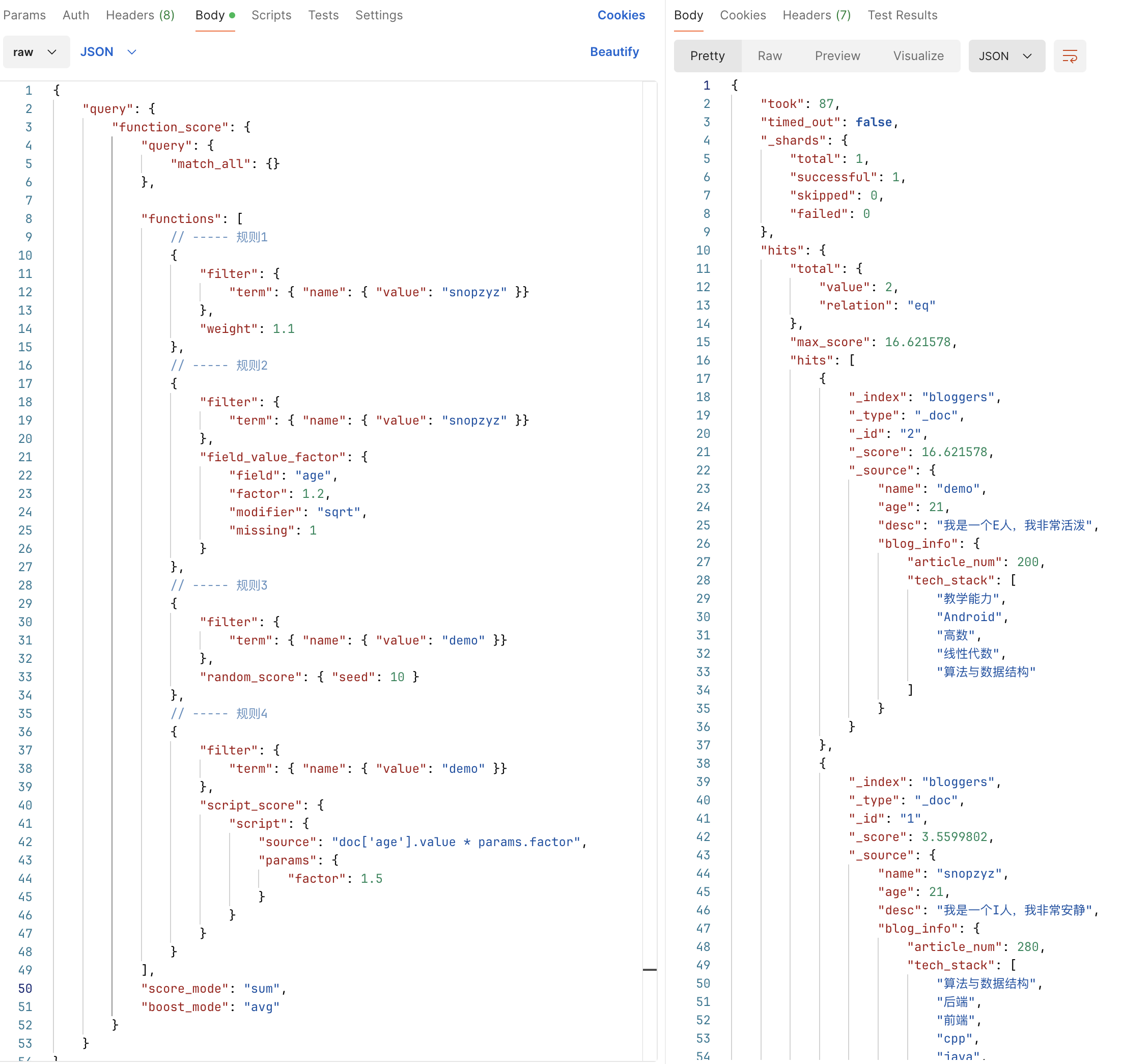
# 加权模式
其中 functions 是一个 Arrays 类型,说明里面可以自定义多个规则,而当多个规则命中同一个文档时,使用 score_mode 进行决定最终 function_score 得分如何计算,计算出的最终 function_score 需要通过 boost_mode 决定如何与 query_score 计算出最终实际得分。
score_mode: 多个 function_score 的组织形式
- multiply(默认):相乘
- sum:相加
- avg:平均值
- first:只使用第一个
- max:最大值
- min:最小值
boost_mode: function_score 和 query_score 的组织形式
- multiply(默认):相乘
- replace:仅使用 function_score 得分
- sum:相加
- avg:平均值
- max:最大值
- min:最小值
# 算分返回规则
weight:直接使用常量数字
"functions": [
{
"filter": {},
"weight": "(Number) 固定返回值"
}
]
2
3
4
5
6
field_value_factor:用文档中的某个字段值返回,可进行简单的变换
"functions": [
{
"filter": {},
"field_value_factor": {
"field": "(String) ${字段名}",
"modifier": "(String) ${规则:对field的值直接运算}",
"factor": "(Number) ${对 field 和 modifier 的结果进行乘法的常量}",
"missing": "(Number) ${若字段不存在,默认值}"
}
}
]
2
3
4
5
6
7
8
9
10
11
random_score:随机分数
"functions": [
{
"filter": {},
"random_score": {
"seed": "(Number) ${随机种子}"
}
}
]
2
3
4
5
6
7
8
script_score:计算 Painless 脚本,可以基于文档字段和自定义参数来计算
"functions": [
{
"filter": {},
"script_score": {
"script": {
"scource": "(String) ${计算语句}",
// 自定义参数
"params": {
"${参数名}": "(Any) ${参数值}"
}
}
}
}
]
2
3
4
5
6
7
8
9
10
11
12
13
14