Stream核心源码逻辑剖析
本篇围绕串行流展开,针对并行流中的很多特殊处理请翻阅后篇。
下面全篇核心内容仍是围绕上文中的例子展开:
List<Integer> list = Arrays.asList(1, 2, 3, 4);
list.stream()
.filter(x -> {
System.out.println("filter1 x=" + x);
return true;
})
.limit(4)
.map(x -> {
System.out.println("map1 x=" + x);
return x;
})
.map(x -> {
System.out.println("map2 x=" + x);
return x;
})
.distinct()
.forEach(x -> {
System.out.println("forEach x=" + x);
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
一组完整的流调用语句,也是一个完整的链表构造过程,仅当最后的 TERMINAL 操作被注册调用时,才代表执行前面的所有语句。
# HEAD的注册
流调用的第一句 list.stream() 代表着“生成一个流”,其底层则是生成一个操作链表的头节点(HEAD 操作)。
为了保证真正执行的时候,可以从头节点拿到原始流,这个节点在内部塞了该流的 Spliterator。
- (List extends Collection)#stream
- StreamSupport#stream(spliterator, ...)
- ReferencePipeline.Head<>#Head(spliterator, ...)
- StreamSupport#stream(spliterator, ...)

没什么重要逻辑,都是些模型异构。
但 spliterator 的实现结构各有千秋,有各个具体容器专门的实现(HashMap.KeySpliterator、ArrayListSpliterator、...),还有 Stream 工具类生成流时对应跟方法名绑定的实现(Streams.RangeIntSpliterator、InfiniteSupplyingSpliterator、...)。
这里不细讲这些实现,只需要知道从 spliterator 中可以像迭代器一样取出一个个元素值就够了。
# 中间操作的注册
中间操作则是在链表后面追加一个节点,每个中间操作节点内通常需要实现一个方法:opWrapSink(),在这个方法内实现一个Sink类,这个实现类需要实现三个方法:begin、accept、end。
这三个方法通常各自都是完成自己的特殊逻辑之后,调用下一个节点的同名方法。
本节不涉及并行流,因此先不引入“中间操作-有状态操作”节点内实现的另外的方法:opEvaluateParallel()、opEvaluateParallelLazy()。
也因此将有状态、无状态操作一视同仁。
sink这个起名为“管道”之意,对应管道模式中注册的管道操作
# .filter(...)的实现
点方法看实现是直达的,就不放调用链了。

注释[1]:
这种就是经典的链表追加节点的写法,将 this 作为新节点的 pre 节点,并将新节点返回出来。
class Node { ... void append(Node newNode) { newNode.pre = this; return newNode; } ... }
这里区别一下,这个 filter 方法返回的是将以 “AbstractPipeline 为基类的实现类” 作为节点,组成的链表,这里每个节点(实现类)是“中间操作整体”,包括操作类别、标识等其他属性元素、可通过方法返回的实际操作内容。
而实现类 opWrapSink 方法内返回的 Sink.ChainedReference 的实现类,也就是实现了 begin、accept、end 的才是实际的操作逻辑,这些“Sink实际操作”会在TERMINAL内部执行过程中才会被组织成链表。
注释[2]:
filter 实现了 begin 和 accept。
- begin:调用了 next 节点的 begin,传参 -1 表示不清楚本节点操作后剩余的数量,如果确定的话这里会是一个其他值。
- accept:predicate 是 filter 方法的参数,是客户端写进去的一个返回 true/false 的方法。u 是 spliterator 吐出来的一个元素,也就是流中的一个元素。
accept 内用该参数方法判断是否“过滤”,通过校验的走 next 节点的 accept
# .map(...)的实现
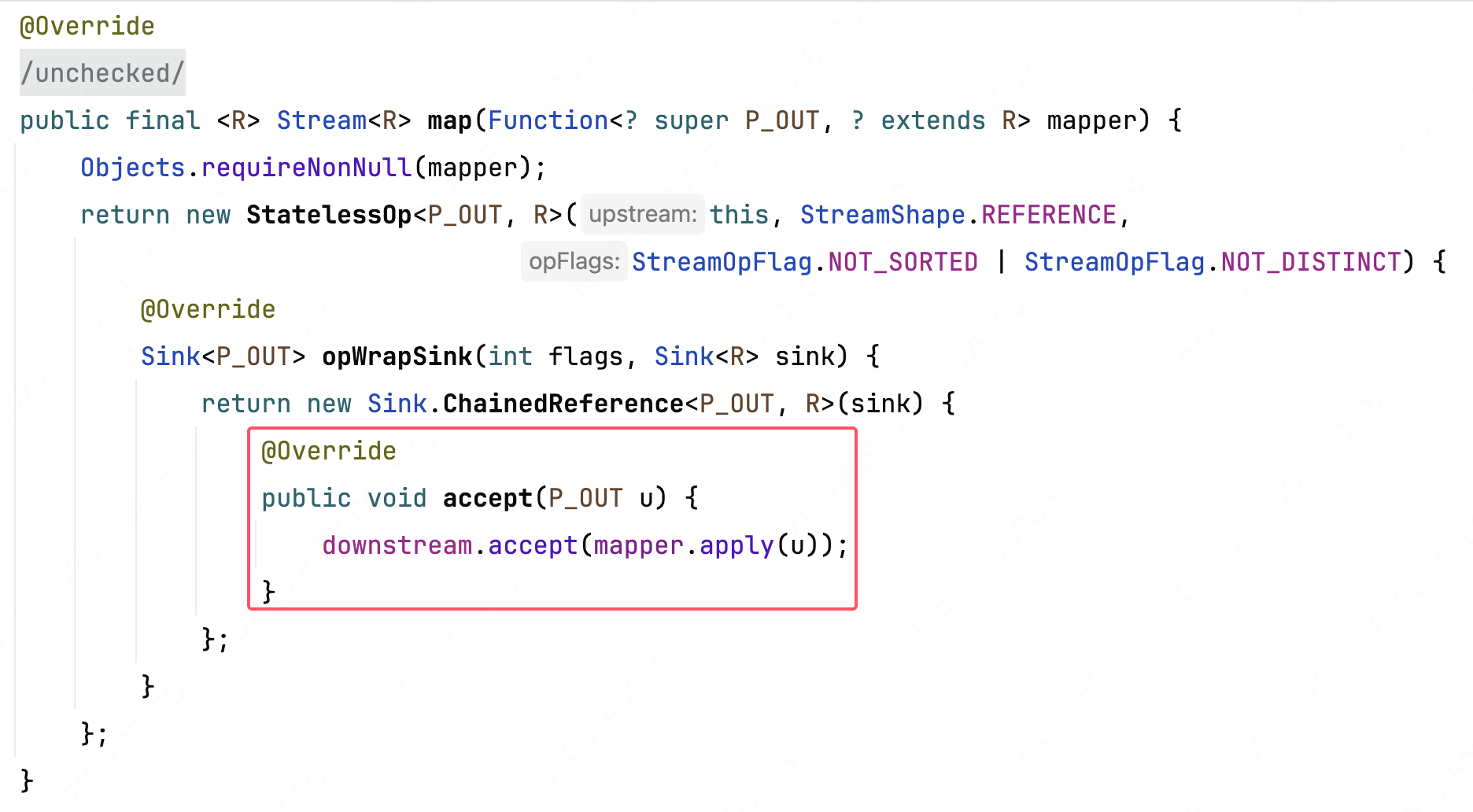
这里有前面的基础了也能很快看懂,就是通过客户端传入 map() 的函数参数,转换流元素 u 为新值。
# .sorted(...)的实现
这个方法注册操作的方式跟前面有一些不同。
- ReferencePipeline#sorted
- SortedOps#makeRef(this)
- SortedOps.OfRef#OfRef
- SortedOps#makeRef(this)
调用链到这里就可以了,可以看出 sorted 返回的就是 SortedOps.OfRef 这个类,而这个类也是被设计了一个 opWrapSink 方法

分别说一下这里的三个分支
- 第一个if:优化,如果前面注册的操作或者流已经有序,则不在这里加入新的 sort 操作。
- 第二个if:优化,如果前面注册的操作或者流已知大小,则进行优化后的 sort 操作(下面说)
- 第三个if:常规的 sort 操作
这里第二第三个分支生成的实现类的逻辑是相似的,先讲解其中一个实现类的操作
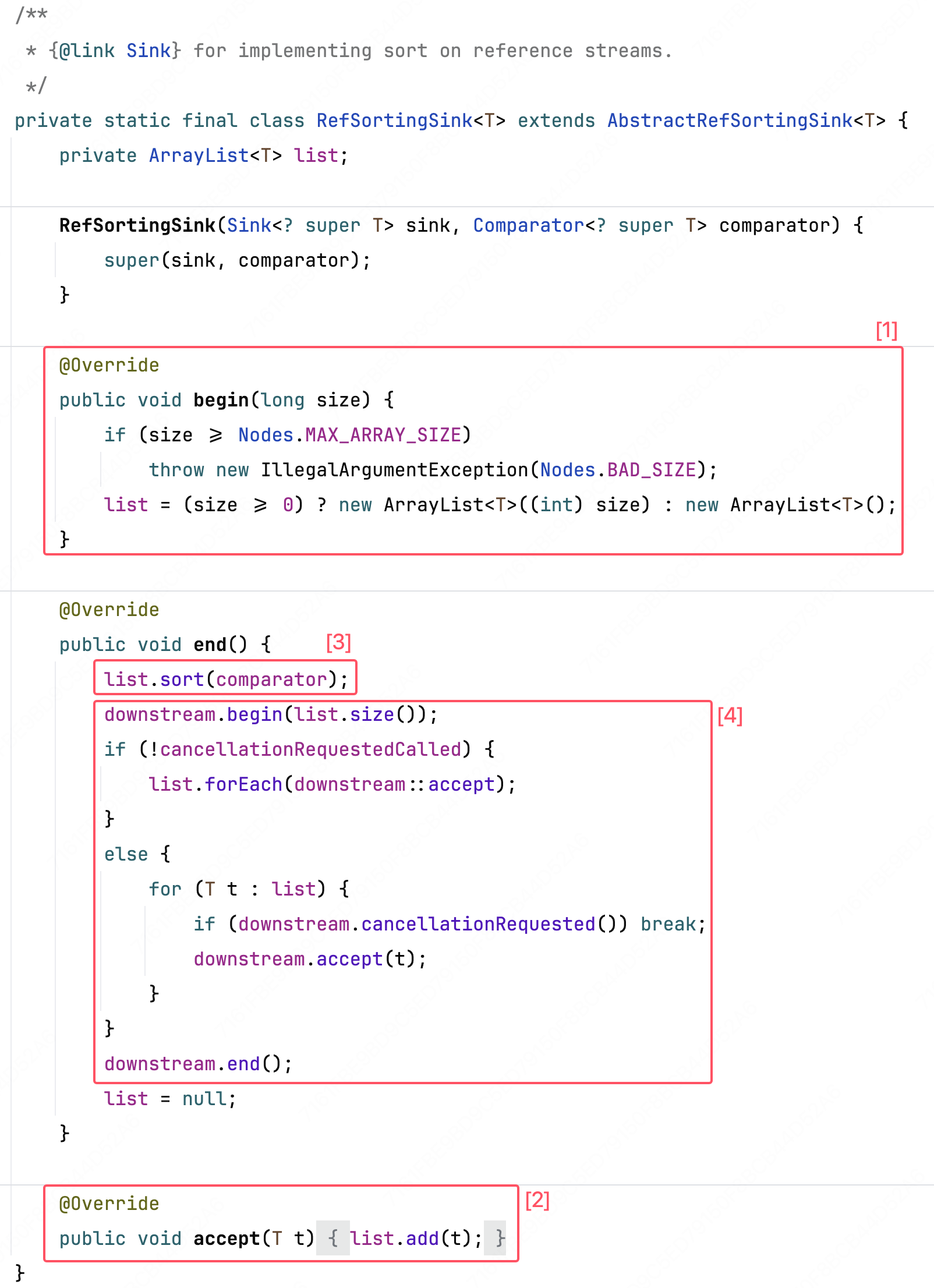
这个实现类中也是实现了 begin、accept、end 三个方法,为方便理解先简单介绍一下最上游(终端操作启动执行)的调用顺序。已知注册的多个流操作形成了一个链,最上游先调用一次 begin,再依次传入流元素调用 accept,最后调用一次 end。
在 sort 操作的实现中:
- 注释[1]:begin 生成一个内部列表
- 注释[2]:accept 多次被调用,依次将上游传下来的所有流元素收集到内部列表中
- 注释[3]:end 对内部列表排序
- 注释[4]:因为需要拿到所有数据进行排序,begin、accept 均不向下调用,因此 end 需要模拟最上游-终端的调用规则向下流转数据
至于上面说的针对有限数量元素的优化,则是将内部 ArrayList 换成了 T[] 数组,通过精确分配内存、无需扩容,提升性能、降低内存占用率。
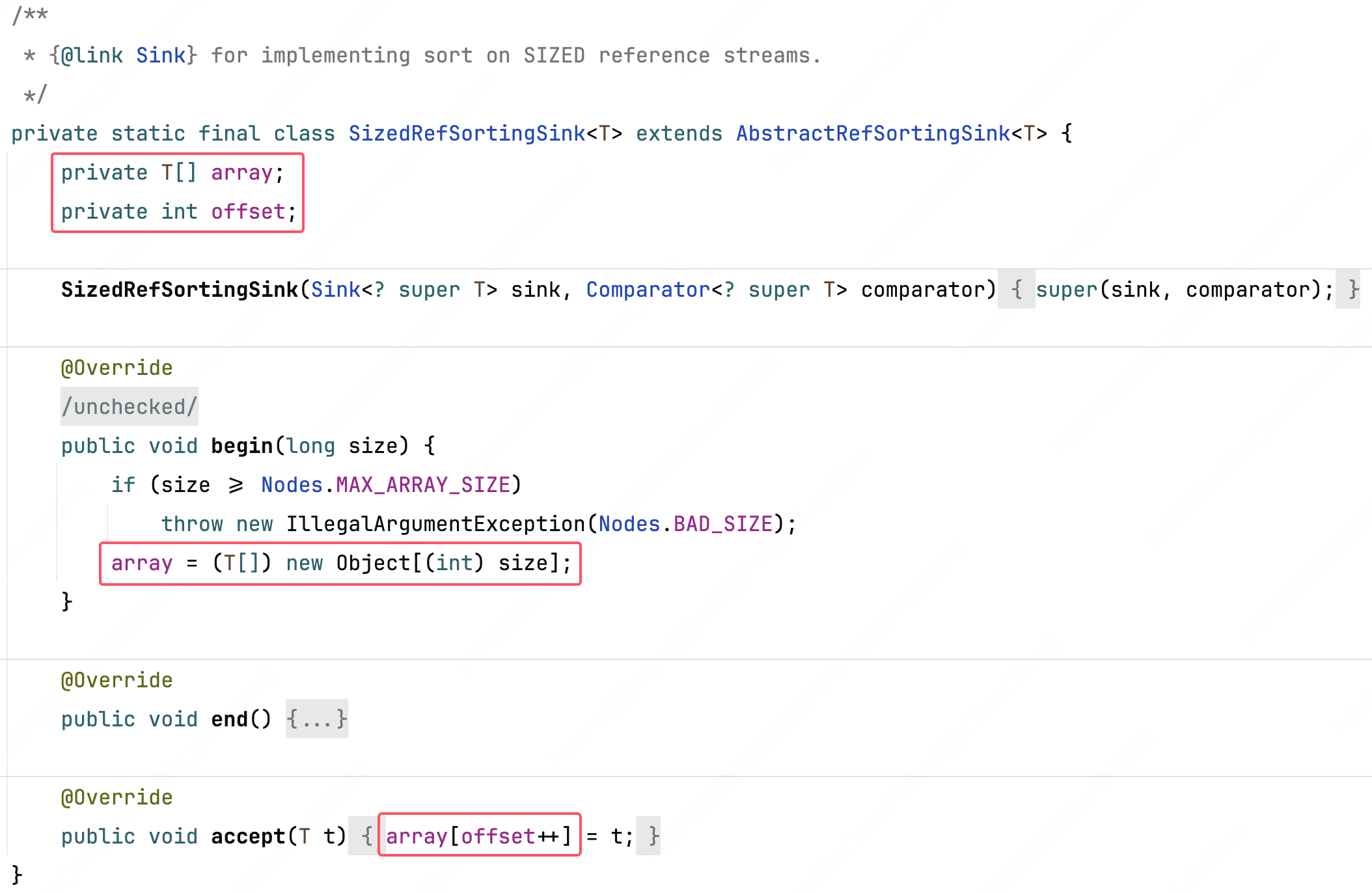
# .limit(...)的实现
这是一个短路操作,会额外实现一个 cancellationRequested 方法。
- ReferencePipeline#limit
- SliceOps#makeRef
依旧和前面一样,看返回的类中实现的 opWrapSink 方法
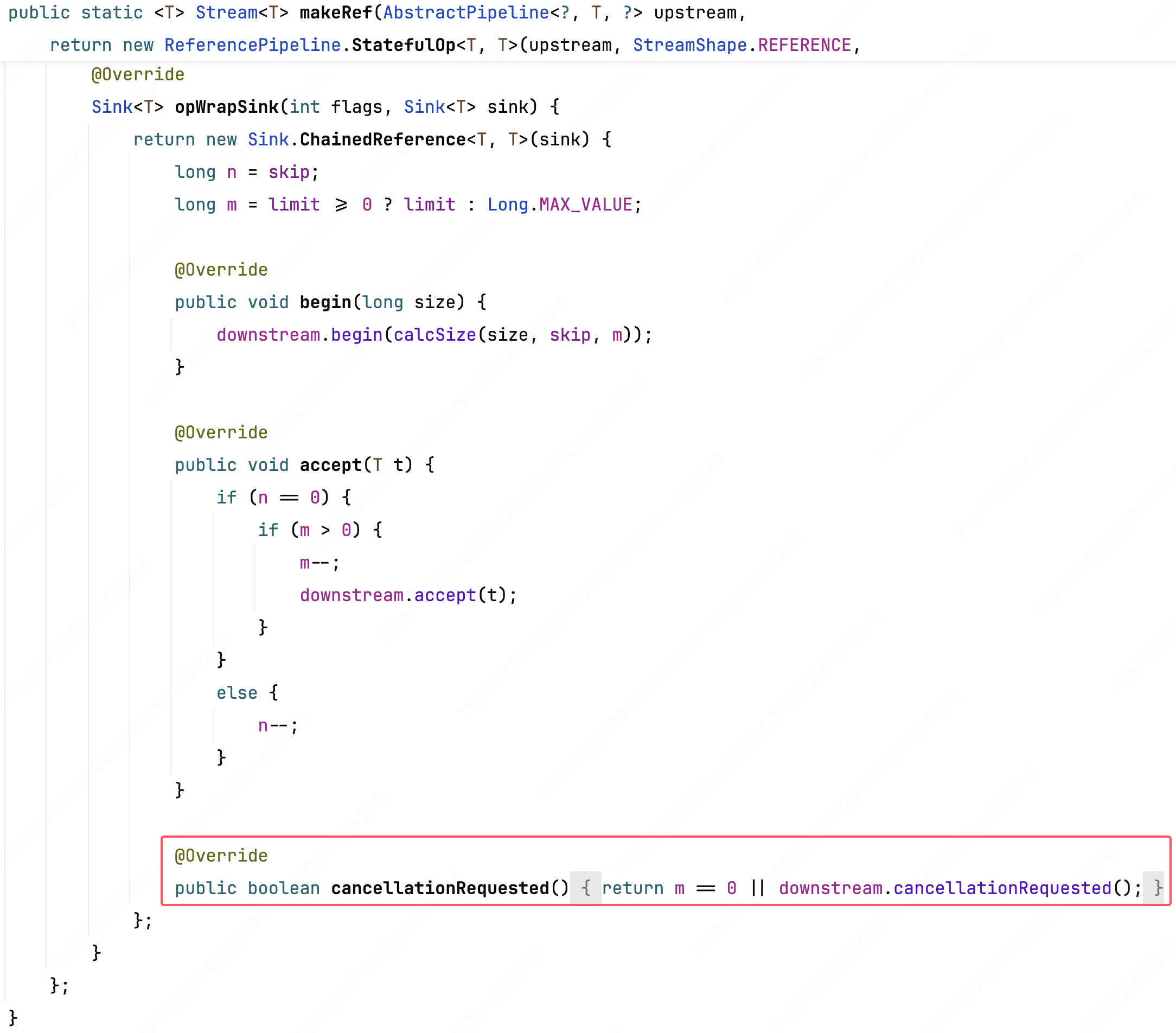
这段代码上面这里都不细讲了,很好理解,只需要介绍下有 skip 和 limit 两个参数是因为这段代码是 Stream.limit(...) 和 Stream.skip(...) 都会走到的。
新实现的这个方法是用来判断当前流元素是否停止处理的,这个方法的调用时机在 accept 之前。
当前实现的逻辑就是判断若已处理元素达到 limit 参数值了,或是下游 cancellationRequested 返回 true 了,就返回 true-停止执行。
# TERMINAL操作的执行
终端操作主要逻辑通常分为三步:
- 实现一个继承于 TerminalSink(extends Sink) 的类,按需实现 beign、accept、end,负责不同终端操作的定制逻辑
- 通过由 AbstractPipeline 的实现类组成的中间操作链,依次调用节点中的 opWrapSink 方法拿到 Sink 类,并将其按操作链顺序,组织成一条新的 Sink 链(包含终端操作的Sink实现类)
- 调用链的 begin 方法,依次拿流元素(对于中间穿插短路操作的,这里还要调用一下 cancellationRequested 方法)调用 accept 方法,调用链的 end 方法
依旧拿两个示例:
# .forEach(...)的实现
核心调用链和需要细讲内容如下
- ReferencePipeline#forEach
- ForEachOps#makeRef
- ForEachOp.OfRef#OfRef - [1]
- ReferencePipeline#evaluate
- ForEachOp#evaluateSequential - 串行流会从上游方法进入这里
- AbstractPipeline#wrapAndCopyInto
- AbstractPipeline#wrapSink - [2]
- AbstractPipeline#copyInto - [3]
- Spliterator#forEachRemaining - 不存在短路操作走这里
- AbstractPipeline#copyIntoWithCancel- 存在短路操作走这里
- ReferencePipeline#forEachWithCancel - [4]
- AbstractPipeline#wrapAndCopyInto
- ForEachOp#evaluateSequential - 串行流会从上游方法进入这里
- ForEachOps#makeRef
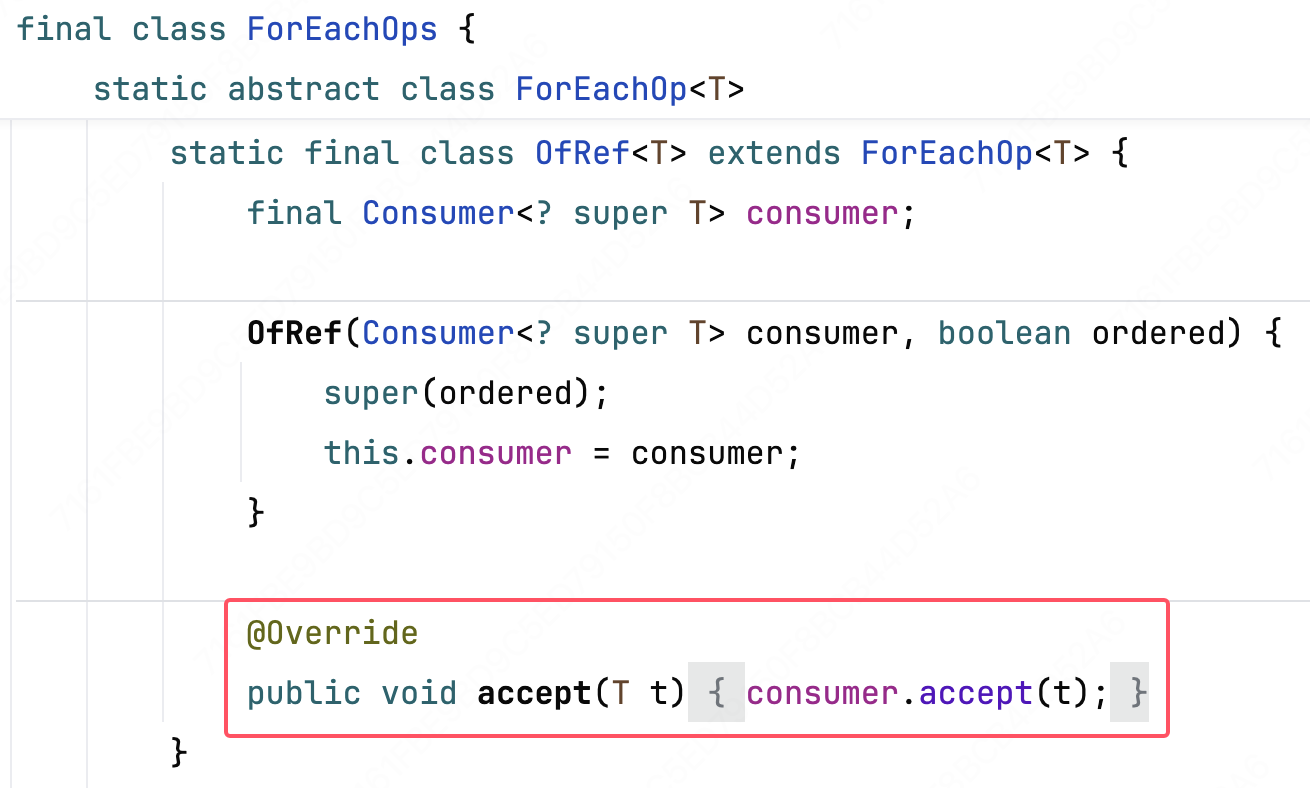
[1] ForEachOp.OfRef#OfRef
这里就是前面说的,终端操作实现了一个自己的 Sink,当前实现的 accept 方法逻辑就是调用客户端传入的函数参数。
[2] AbstractPipeline#wrapSink
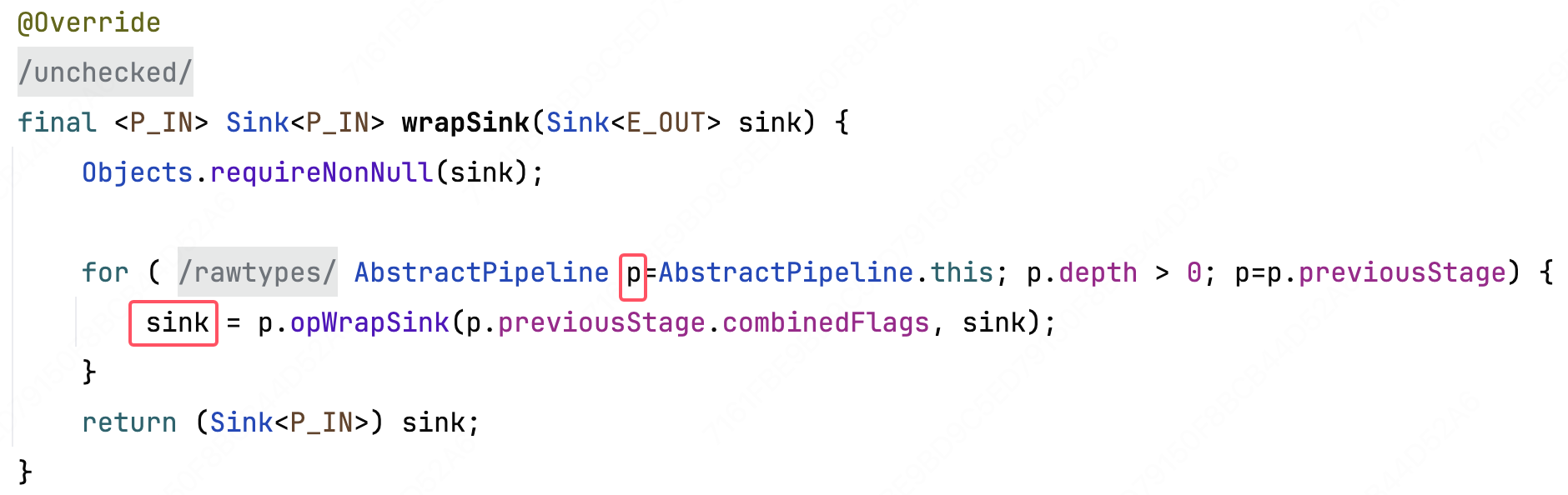
这段代码是生成新的 Sink 链的过程,主要需要分清变量 p 和 sink
- p 是 AbstractPipeline 也就是整个中间操作链的节点指针,它从链尾向链头遍历
- sink 是 opWrapSink 方法生成的,存放实际操作的实现类实例,随着 p 的遍历,自组出新的 sink 链表,最后返回头节点sink
[3] AbstractPipeline#copyInto

这里是 sink 链的执行逻辑,为了方便理解我把原 copyIntoWithCancel 方法拆出来了。
主要内容都差不多,都是前面说的 begin、forEachXXX、end,唯一的差别是根据操作链中是否短路,来区分调用哪个方法。
[4] ReferencePipeline#forEachWithCancel
这个方法和 spliterator.forEachRemaining 差别不大,这两个方法核心都是取 spliterator 流中的一个元素,走 sink 链的 accept。
只是这个方法在 accept 前,会走 sink 链的 cancellationRequested 判断后续是否需要执行,这也是短路操作的一个特点。
代码可读性优化后如下:

tryAdvance 方法内主要就是执行 accept,只是针对不同容器/流,取元素的方式不同。
# .count()的实现
核心调用链和需要细讲内容如下
- ReferencePipeline#count
- ReferencePipeline#mapToLong - 比较有意思的点:在这里注册了个中间操作,将每个元素变成1,后续用来求和计数
- LongPipeline#sum
- LongPipeline#reduce
- ReduceOps#makeLong - [1]
- AbstractPipeline#evaluate - 到这里跟上面就一样了,就不说了
- ...
- LongPipeline#reduce
[1] ReduceOps#makeLong
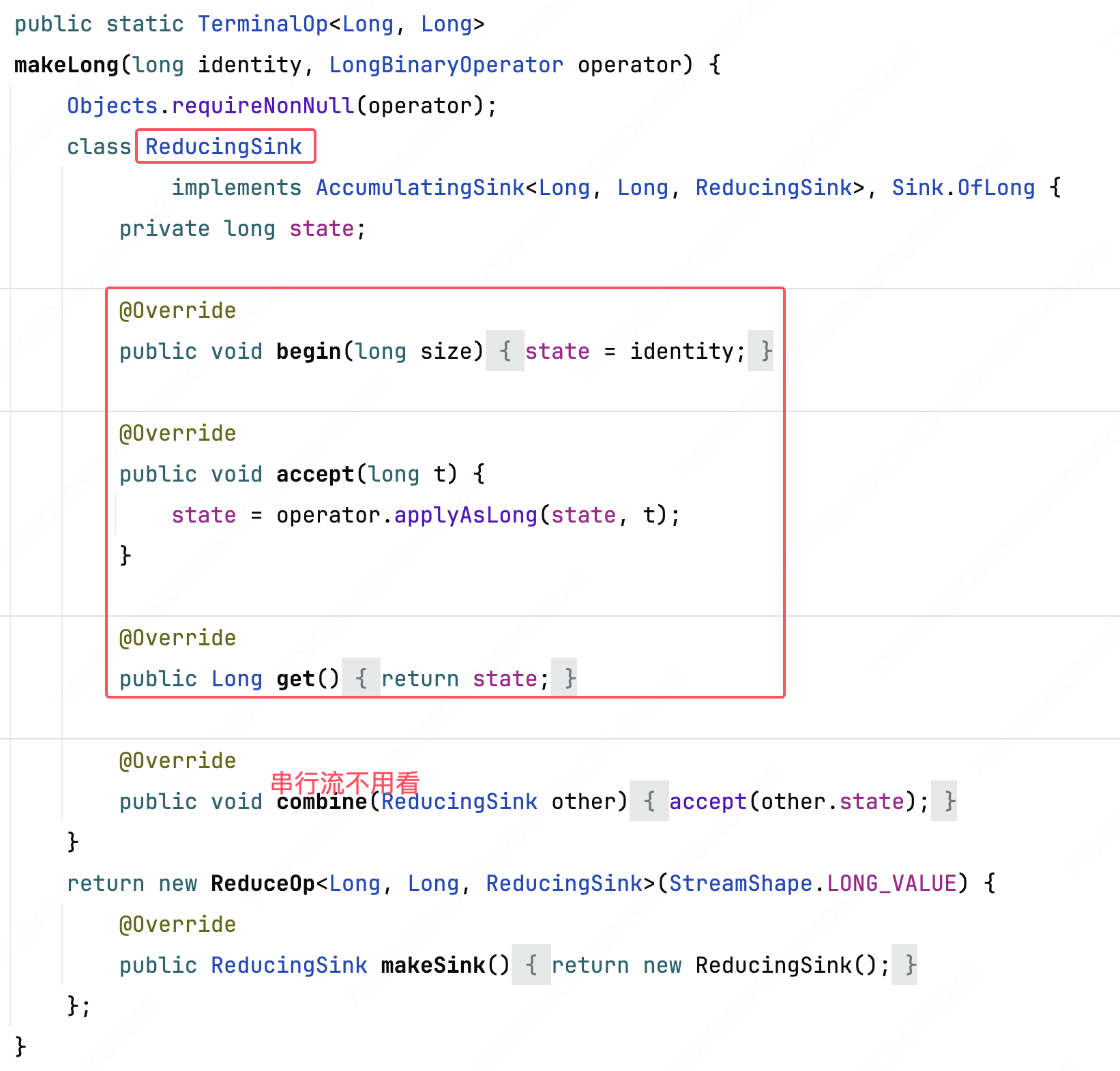
这里也是用来实现了个终端Sink操作,其中 operator 在这里传入的是 Long#sum,意味着在 accept 中是对前面转换成的 1 进行求和。
# 结语
剩余的 StreamAPI 还有很多,这里不可能都讲。
但是万变不离其宗,核心链路都已经理出来了,剩下的感兴趣可以自行翻阅 ~