行为型 - 管道(Pipeline)
# 概述
管道模式通过将数据流经一系列独立的处理步骤(管道)来实现数据的逐步转换和处理,每个步骤独立且复用。 数据只要符合条件,会一直向下传递,不会停止。
管道模式和责任链模式比较像,都是通过责任节点的链式执行(每个 Handler 保存一个后继 Handler 链式向下传递)来处理的。
但是上面也说了,管道模式对符合条件的数据会一直传递处理,而责任链是数据单元最多只会有一个 Handler 会处理,处理之后就不向下进行了。
责任链案例:多级缓存
多级缓存的实现,每一级缓存都是一个责任节点。
当一个查询单元被某一级缓存或远程接口查询到,该查询单元便不再会乡下处理了。
# 实现
管道模式有三种成员:
- 处理接口类:
IHandler- 后继处理类:
IHandler nextHandler - 执行处理:
handle()
- 后继处理类:
- 处理实现类:
HandlerImpl,主要实现handle() - 管道(控制器):
Pipeline- 处理实例头结点:
IHandler head - 添加处理实例:
addHandler(IHandler) - 执行处理:
handle()
- 处理实例头结点:
它们的组织关系如下

下面做一个简单示例,功能是处理字符串,设计两个 Handler
- 清除首尾空字符
- 将大写全部转换为小写
先实现两个 Handler 规范类 IHandler、AbstractHandler ,写成泛型较为规范,方便之后扩展。
AbstractHandler 稍微改一下上面 uml 图中演示的,把执行核心处理逻辑、调用下层 handler 逻辑封装在一起形成 handle(),并扩展出一个 Handler 核心业务处理方法 action(),使继承它的仅关注 action() 即可。
public interface IHandler<T> {
void handle (T body);
}
public abstract class AbstractHandler<T> implements IHandler<T> {
@Setter
@Getter
private AbstractHandler<T> nextHandler;
protected abstract void action (T body);
/**
* 设置为 final 令子类不可更改
*/
@Override
public final void handle (T body) {
// 执行本 Handler 处理
action(body);
// 向下发送数据
if (nextHandler != null) {
nextHandler.handle(body);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
然后是管理器 Pipeline,主要功能是构造以 AbstractHandler 为元素的链表,并向外开放一个执行 Handler 的方法。
public class Pipeline<T> {
// 首元节点
private AbstractHandler<T> head;
// 终端节点
private AbstractHandler<T> tail;
/**
* 链式执行 handler
*/
public void execute (T body) {
if (body == null || head == null) {
return;
}
head.handle(body);
}
/**
* 向尾部追加 handler
*/
public void addHandler (AbstractHandler<T> handler) {
if (head == null) {
head = tail = handler;
} else {
tail.setNextHandler(handler);
tail = handler;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
到这就已经把核心结构搭好了,接下来就是实现两个处理字符串的功能 Handler 了,因为都有现成的 StringUtils 可以调用,就不细讲 action 里面怎么写了
/**
* 先声明一个简单的包含一个字符串的类 Request
*/
@Data
@AllArgsConstructor
public class Request {
private String str;
}
/**
* 将 Request.str 全部替换为小写
*/
public class LowerHandler extends AbstractHandler<Request> {
@Override
protected void action(Request request) {
if (request == null) {
return;
}
request.setStr(
StringUtils.lowerCase(request.getStr()));
System.out.println("LowerHandler 执行后,request.str=\"" + request.getStr() + "\"");
}
}
/**
* 将 Request.str 去除首尾空白字符
*/
public class TrimHandler extends AbstractHandler<Request> {
@Override
protected void action(Request request) {
if (request == null) {
return;
}
request.setStr(
StringUtils.trim(request.getStr()));
System.out.println("TrimHandler 执行后,request.str=\"" + request.getStr() + "\"");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
最后写一个 Demo 注册一下 Handler 然后调用执行看看结果
public class PipelineDemo {
public static void main(String[] args) {
Pipeline<Request> pipeline = new Pipeline<>();
pipeline.addHandler(new TrimHandler());
pipeline.addHandler(new LowerHandler());
Request request = new Request(" Hello_World ");
System.out.println("最初状态:\"" + request.getStr() + "\"");
pipeline.execute(request);
System.out.println("最终结果:\"" + request.getStr() + "\"");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
按预期先进行 trim 将原参数 " Hello_World " 变为 "Hello_World",再进行小写转换变为 "hello_world"

结果符合预期。
# 延伸
有个有意思的事情,管道的这种行为似是对流经的水流进行处理。
而看 Java8 的流操作 StreamAPI 的源代码可以发现,它也是按照管道模式进行设计的。
这里不会细致讲关于它是怎么做的,就只带着看一小块。
Stream#filter (ReferencePipeline.java内)

其定义了一个匿名类,在 accept() 方法中通过 filter 的核心校验方法 test() 后,将数据发送给下一层 Sink.accept()
Stream#map (ReferencePipeline.java内)
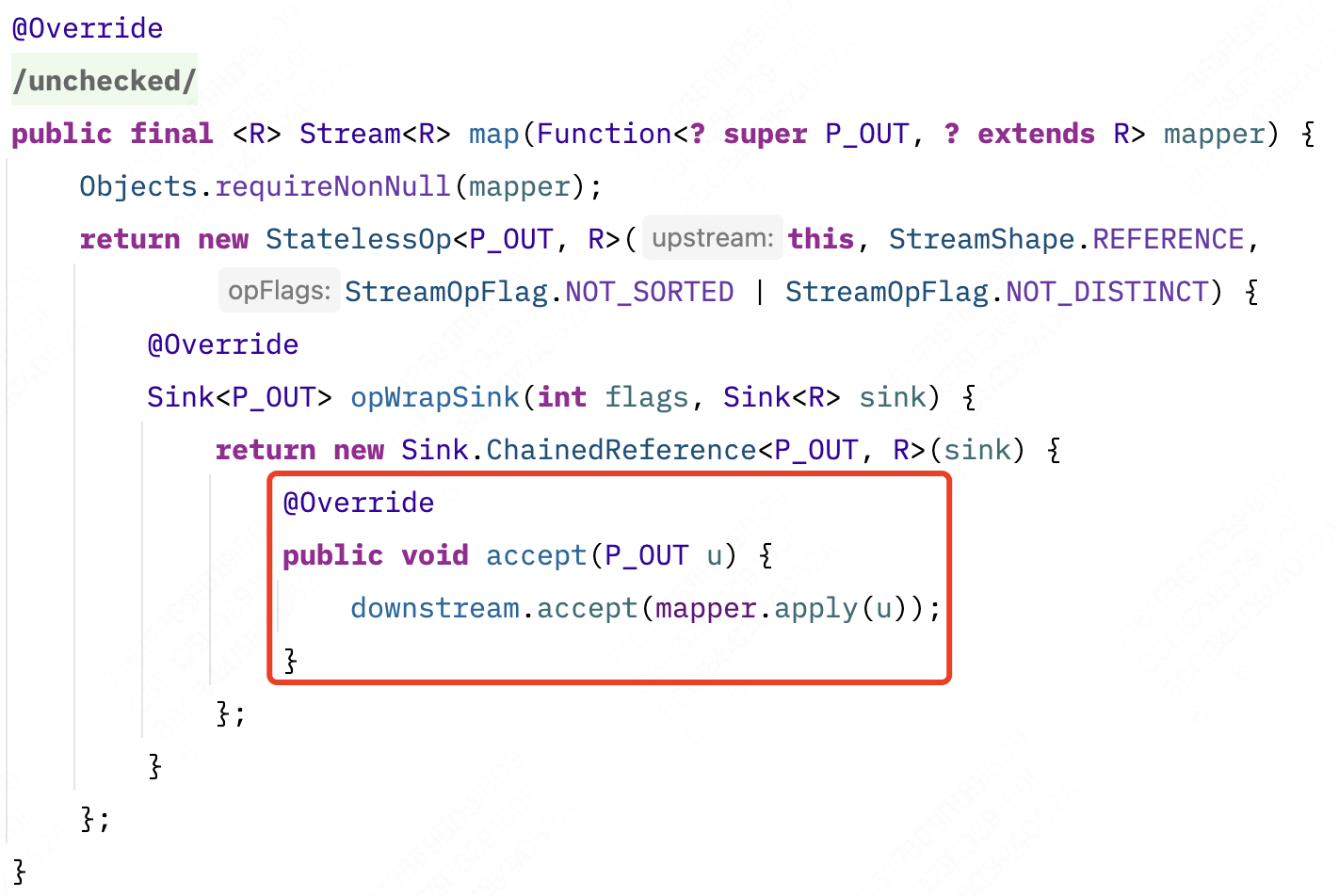
一样的,在匿名类的 accept() 中,将接受完 mapper.apply 转换后的数据发送给下一层的 Sink.accept()
它甚至连实现了 Stream 的抽象类也命名成 AbstractPipeline....